![[←]](common_files/screen-return.gif) ./a.out
src
dst
$
./a.out
src
dst
$

理解を深めるために
| 第1回 | |
| 第2回 | |
| 第3回 | |
| 第4回 | |
| 第5回 |
ファイルアクセスをするには,システムコールを用いる方法と,ライブラリ関数を用いる方法がある. どちらにせよ手順は同じで,アクセスしたいファイルを開き (open) ,読み書き (read, write) を行い,最後に閉じる (close).
ライブラリを用いたファイルの入出力において,ファイルを開き,閉じるためには fopen, fclose を用いる. 読み書きのためには,標準入出力で述べた関数のうち,先頭に f がついている関数が使用できる. 引数で指定できる FILE *stream を,stdin, stdout の代わりに,fopen の戻り値として得られる値にすればよい. ファイルの入出力で便利な fread, fwrite という関数も用意されている(これらは標準入出力に対しても用いることができる).
FILE *fopen(const char *path, const char *mode); int fclose(FILE *stream); size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream); size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
ファイルを開くために使用する fopen の戻り値の型は FILE * (FILE 構造体へのポインタ,通称,ファイルポインタ)である. 1文字入力の fgetc は,読み込み元として引数に FILE * 型のデータを受け取り,1文字出力の fputc は引数に文字の他に書き込み先として FILE * 型のデータを受け取る.
つまり,ライブラリを用いたファイルアクセスにおいては,ファイルポインタがファイルの代理人のようなものになる.
FILE 構造体は,読み書きしているファイル,ファイルに対し許される操作(読み込み,書き込み,または両方),現在ファイルのどの部分をアクセスしているのか,エラーは起きていないか,などの情報を持つ. ファイルポインタはこの構造体へのポインタになっており,ファイルポインタを指定することにより,対応するファイルの読み書きを行うことができるようになっている.
fgetc, fputc を用いて標準入力から読み込み,標準出力へ書き出すプログラムは,fopen, fclose を前後に入れる変更によって簡単に,ファイルのコピーを行う以下のプログラムになる.
filecopy-lib1.c
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 int main(void)
5 {
6 int c;
7 FILE *src, *dst;
8
9 src = fopen("src", "r");
10 if (src == NULL) {
11 perror("src");
12 exit(1);
13 }
14
15 dst = fopen("dst", "w");
16 if (dst == NULL) {
17 perror("dst");
18 fclose(src);
19 exit(1);
20 }
21
22 while ((c = fgetc(src)) != EOF)
23 fputc(c, dst);
24
25 fclose(src);
26 fclose(dst);
27
28 return 0;
29 }
2行目の stdlib.h は,12行目,19行目の exit の宣言を含む.
9行目の fopen では,読み込み元のファイルとして "src" ,オープン時のモードとして "r" を指定している. モードは,オープンされたファイルに対しこの後に許される操作および,どこから読み書きが始まるかを決定する. "r" は,ファイルを読み込みのためにオープンすることを意味し,ファイルの先頭から読み込みが始まる.
14行目の fopen では,書き込み先のファイルとして "dst" ,オープン時のモードとして "w" を指定している. "w" は,ファイルを書き込みのためにオープンすることを意味し,ファイルが存在しない場合には新たに作られ,存在する場合にはそのファイルの内容は消されてファイルの長さは 0 にされる. また,書き込みはファイルの先頭から始まる.
他にモードとして指定できる文字列には,r+, w+, a, a+ (つまり rwa の文字のいずれか,またはそれに + を付けたもの)がある. r+, w+, a+ はどれも読み書きのためにファイルをオープンすることを意味するが,ファイルが存在しない場合の動作や,読み書きがどこから始まるか,といった点が異なる. 正確な意味は fopen のマニュアルを参照(man fopen).
モードを指定する文字列に b を含むプログラムを目にすることがあるが,互換性のために残されているだけで,POSIX では意味がない.
10~13行目,16~20行目は fopen に失敗した時の処理である. どちらも,perror によりエラーメッセージを出力した後に,exit によりプログラムの実行を終了させている. exit の引数は,プロセスの終了を待っている親プロセスに渡されるが,この詳細は来週に解説する予定.
18行目では,"src" ファイルへのファイルポインタをクローズするために fclose を呼び出している. exit を実行すると,そのプロセスがオープンした全てのファイルは自動的にクローズされ,そのプロセスが確保したメモリ領域も解放されるため,この fclose は実際は必要ない. しかし exit を呼び出さない場合には,同時にオープンできるファイルには制限があり,またメモリリークが起きないようにするためにも,使用しないファイルを確実にクローズすることは重要である.
ファイルのコピーなどのコマンドのプログラムを作る時には,コピーするファイル名をコマンド行の引数として渡せると便利である. このようなプログラム起動時の引数は,main 関数への引数として渡される. 以下のプログラムは,コマンド行の引数を出力する.
args.c
1 #include <stdio.h>
2
3 int main(int argc, char *argv[])
4 {
5 int i;
6
7 for (i = 0; i < argc; i++)
8 puts(argv[i]);
9
10 return 0;
11 }
これをコンパイル,実行すると以下のような結果が得られる.
$ ./a.out src dst
上記のプログラムの3行目の main 関数の引数として argc, argv が指定されている.argc は int 型,argv は char * 型の配列(char 型へのポインタを格納する配列)である. argc は argument count,argv は argument vector の略である. main 関数の引数の名前は argc, argv である必要はないが,慣例的に argc, argv が使われており,この名前を使うことがプログラムのわかりやすさの点でも望ましい.
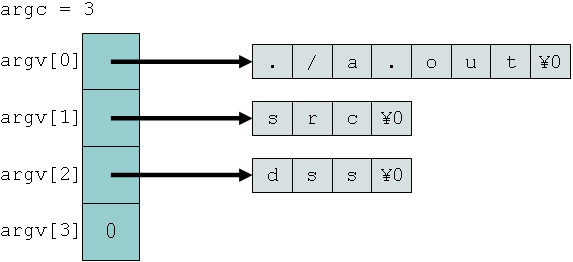
argc には,コマンド行の文字列の個数が入る(コマンド名の文字列も個数に含む). 上記の実行例では argc の値は 3 になる.
argv には,コマンド行の各文字列へのポインタを格納した配列が入る. 下図は,上記の実行例における argv の構造を図示したものである. argv[0] はコマンド名の文字列 "./a.out" , argv[1] は最初の引数 "src" , argv[2] は次の引数 "dst" , そして argv[3] すなわち argv[argc] にはNULLポインタ(要するに 0 )が格納される.
ライブラリ関数を用いてファイルのコピーを行うプログラムを,コピーするファイル名をコマンド行の引数として渡せるようにすると次のようなプログラムになる.
filecopy-lib2.c
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 int main(int argc, char *argv[])
5 {
6 int c;
7 FILE *src, *dst;
8
9 if (argc != 3) {
10 fprintf(stderr, "Usage: %s from_file to_file\n", argv[0]);
11 exit(1);
12 }
13
14 src = fopen(argv[1], "r");
15 if (src == NULL) {
16 perror(argv[1]);
17 exit(1);
18 }
19
20 dst = fopen(argv[2], "w");
21 if (dst == NULL) {
22 perror(argv[2]);
23 fclose(src);
24 exit(1);
25 }
26
27 while ((c = fgetc(src)) != EOF)
28 fputc(c, dst);
29
30 fclose(src);
31 fclose(dst);
32
33 return 0;
34 }
argc, argv を解釈する際には,引数の数をチェックすることが大切である. 上記のプログラムでは 9~12行目で,コマンド行の引数の数が3(すなわちプログラムに与えた引数の数が2)でなければ,そのプログラムの使い方を表示し,プログラムを終了するようにしている.
これをコンパイル,実行すると以下のような結果が得られる.
$ ./a.out
システムコールを用いたファイルの入出力において,ファイルを開き,閉じるためには open, close を用いる. 読み書きのためのシステムコールには read, write を用いる. ライブラリ関数と異なり,read, write 以外には読み書きのためのシステムコールはない.
int open(const char *pathname, int flags); int open(const char *pathname, int flags, mode_t mode); int close(int fd); ssize_t read(int fd, void *buf, size_t count); ssize_t write(int fd, const void *buf, size_t count);
ファイルアクセスのためのシステムコールは上記の open, close, read, write である. ライブラリ関数も,ファイルアクセスを行うために最終的にはシステムコールを使用する. 例えば,fopen は open を呼び,fclose は close を呼ぶ. getchar, fgetc, fgets, fread は read を呼び,putchar, fputc, fputs, fwrite は write を呼ぶ.
fopen は FILE 構造体へのポインタを返す.その後オープンしたファイルにアクセスするためにはそのポインタを用いる. open はオープンに成功すると0以上の整数を返す. その整数は,ファイルディスクリプタ(ファイル記述子)と呼ばれる. システムコールを用いたファイルアクセスでは,open で得られたファイルディスクリプタを指定することにより,read, write を用いてファイルの読み書きを行うことができる. ファイルアクセスが終了したら,ファイルディスクリプタを引数にして close を呼ぶと,ファイルをクローズできる.
あるプロセスが一時にオープンできるファイルの数(ファイルディスクリプタの最大値)は制限されている. 昔の UNIX では非常に少なかったが,現在はかなり多くのファイルを一時にオープンすることができる. Mac OS X では,通常のプロセスは 256 に設定されている(ulimit -n を実行すると値を確認できる). ulimit コマンドにより最大 10240 まで使用可能にできる(/usr/include/sys/syslimits.h の OPEN_MAX を参照).
ライブラリ関数による入出力も結局はシステムコールを呼び出すことで実現されている. ということは,標準入出力(stdin, stdout, stderr)への入出力も,システムコールによって処理されている. システムコールによる入出力では,ファイルディスクリプタにより入出力先が指定されるため,標準入出力のためのファイルディスクリプタもなければおかしいことになる.
標準入出力のためのファイルディスクリプタとして0, 1, 2が割り当てられている. 0が標準入力,1が標準出力,2が標準エラー出力に対応する. これら3つのファイルディスクリプタは,プログラムが実行される時に明示的にオープンしなくても,使える状態になっている.
ライブラリ関数を用いてファイルのコピーを行うプログラムを,システムコールを用いるように書き換えると以下のプログラムのようになる.
filecopy-syscall.c
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <fcntl.h>
4 #include <unistd.h>
5
6 int main(void)
7 {
8 char c;
9 int src, dst;
10 int count;
11
12 src = open("src", O_RDONLY);
13 if (src < 0) {
14 perror("src");
15 exit(1);
16 }
17
18 dst = open("dst", O_WRONLY | O_CREAT | O_TRUNC, 0666);
19 if (dst < 0) {
20 perror("dst");
21 close(src);
22 exit(1);
23 }
24
25 while ((count = read(src, &c, 1)) > 0) {
26 if (write(dst, &c, count) < 0) {
27 perror("write");
28 exit(1);
29 }
30 }
31
32 if (count < 0) {
33 perror("read");
34 exit(1);
35 }
36
37 close(src);
38 close(dst);
39
40 return 0;
41 }
プログラムの流れは,ライブラリ関数を用いた場合と同じである. open の引数は,オープンしたいファイル名と,どのようにオープンするかを指示するためのフラグである. O_RDONLY は読み込みのみ,O_WRONLY は書き込みのみを意味する. 読み込みと書き込みの両方を行うファイルのオープンでは O_RDWR を指定する. O_RDONLY, O_WRONLY, O_RDWR と一緒に設定できるフラグがいくつかある. O_CREAT がセットされていると,ファイルが存在しない場合にファイルを作成する. O_TRUNC がセットされていると,ファイルが存在する場合にファイルの内容が消されてファイルの長さは 0 にされる. フラグに O_CREAT が含まれる場合には,ファイルが作られた場合に設定するパーミッションを第3引数として与える. 実際に設定されるパーミッションは,引数で与えられたパーミッションに umask のマスクがかかった値になる.
read では読み込む最大バイト数,write では書き込む最大バイト数を指定するが,それぞれ指定されただけの最大バイト数を読み込みまたは書き込みできるとは限らない. 実際に読み書きされたバイト数が read, write の戻り値として返される.
read, write の引数で指定する読み書きの最大バイト数は大きくしておいたほうが,read, write システムコールの呼び出しとコピーの回数が少なくてすむので,より効率的である. つまり上記のプログラムのように1とするのは,非常に効率が悪い. 通常4096, 8192, 16384などの値が用いられるが,最も効率の良い値は入出力先のデバイス,デバイスを制御するコントローラ,メモリの量などに依存する.
ライブラリとシステムコールを混ぜて同一のファイルをアクセスすることは,プログラミング上は可能ではあるが,結果がおかしくなる可能性があるので,避けるべきである. ライブラリ関数での入出力は,1文字単位の入出力も効率よく行えるように,入出力データを一時的に蓄えるバッファリングをすることで,システムコールの回数を減らしている. 混ぜて使うと,バッファリングされたデータとの整合性が取れなくなってしまう.
ファイルディスクリプタとファイルポインタのどちらかからどちらかへどうしても変換したい時には,以下の関数を使用することができる. fileno, fdopen は,十分なテストをするなどして何をしているのか理解した上で注意して使用すべきであり,安易に使用すべきではない.
fflush は,上記の目的とは関係なく,バッファリングされたデータをフラッシュ(すぐに出力)したい時にも使用できる.
int fileno(FILE *stream); /* FILE 構造体のファイルディスクリプタを返す */ FILE *fdopen(int fildes, char *mode); /* ファイルディスクリプタから FILE 構造体を作る */ int fflush(FILE *stream); /* バッファリングされたデータをフラッシュ */
全てをメモリ上に読み込むことが難しい大きなデータを扱う場合,全データはファイルに格納し,必要なデータのみを読み書きすることになる. その場合,データをファイルの先頭から順番に読み込んでいくシーケンシャルアクセスではなく,途中を読み飛ばす(読み書きする場所を移動する)ランダムアクセスができると効率が良い.
ランダムアクセスをするためには,システムコールの read, write を用いている場合には lseek,ライブラリ関数の fread, fwrite を用いている場合には fseek を用いる. これらの関数は,ファイルを読み書きする位置(ファイルの先頭からのバイト数)を変更する. この位置のことを,オフセット,シークポインタ,ファイルポインタなどと呼ぶ(ファイルポインタと呼ぶ場合は FILE * と紛らわしいので注意).
off_t lseek(int fildes, off_t offset, int whence); int fseek(FILE *stream, long offset, int whence);
lseek, fseek 共に指定するパラメータは同じで,第3引数の whence で指定される位置に第2引数の offset バイト数を加えることによって得られた位置に移動する. offset に負の値を指定すると,whence で指定された位置から前に移動する. whence には以下のマクロのどれかを指定する.
| SEEK_SET | ファイルの先頭から offset バイト目に移動. |
| SEEK_CUR | 現在の位置から offset バイト目に移動. |
| SEEK_END | ファイルの末尾から offset バイト目に移動. |
SEEK_END によりファイル末尾から先頭方向に向かって offset バイト目に移動したい場合には(通常そうであると思われるが),offset には負の値を指定しなければいけないことに注意.
fread, fwrite はライブラリで実装されており,バイト単位での入出力も効率良く行えるように,バッファリングしている. また,指定したオブジェクト(レコード)単位での読み書きを保障しているため,システムコールの read, write と比較して使いやすい.
fread, fwrite は内部でバッファリングをするが,それとは別に,fread, fwrite にデータを渡すためのバッファをプログラムの中で確保する必要がある. そのバッファを malloc で確保するプログラムの例を以下に示す.
filecopy-buf.c
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 int main(int argc, char *argv[])
5 {
6 FILE *src, *dst;
7 void *buf;
8 int rcount, wcount;
9
10 if (argc != 3) {
11 printf("Usage: %s from_file to_file\n", argv[0]);
12 exit(1);
13 }
14
15 src = fopen(argv[1], "r");
16 if (src == NULL) {
17 perror(argv[1]);
18 exit(1);
19 }
20
21 dst = fopen(argv[2], "w");
22 if (dst == NULL) {
23 perror(argv[2]);
24 fclose(src);
25 exit(1);
26 }
27
28 buf = malloc(BUFSIZ);
29 if (buf == NULL) {
30 perror("malloc");
31 fclose(src);
32 fclose(dst);
33 exit(1);
34 }
35
36 while (!feof(src)) {
37 rcount = fread(buf, 1, BUFSIZ, src);
38 if (ferror(src)) {
39 perror("fread");
40 fclose(src);
41 fclose(dst);
42 exit(1);
43 }
44
45 wcount = fwrite(buf, 1, rcount, dst);
46 if (ferror(dst)) {
47 perror("fwrite");
48 fprintf(stderr, "tried to write %d bytes, "
49 "but only %d bytes were written.\n",
50 rcount, wcount);
51 fclose(src);
52 fclose(dst);
53 exit(1);
54 }
55 }
56
57 fclose(src);
58 fclose(dst);
59
60 return 0;
61 }
28行目で malloc でバッファを確保している. 確保する領域のサイズを指定している BUFSIZ は標準的なバッファサイズを表すマクロであり,stdio.h で定義されている. 38行目にある feof は,fread の戻り値からは EOF とエラーの区別ができないため,EOF かどうかを調べるために使用している. 38, 46行目にある ferror は,同様の理由で,エラーが発生したかどうかを調べるために使用している.
まとめて扱うと便利なデータは,C プログラムでは構造体を用いて表現する. 例えば住所録を作る場合,名前,住所,電話番号,メイルアドレスなどを構造体としてまとめて扱うと,ソートや検索などの様々な処理がしやすくなる.
構造体のデータをファイルに保存し,読み出すために,まず知らなくてはならないことは構造体の大きさである. 住所録のそれぞれのエントリのために,以下のような構造体を定義したとする.
addr.h
1 struct entry {
2 char name_family[32];
3 char name_first[32];
4 char addr[128];
5 int zip1;
6 int zip2;
7 char mail[128];
8 };
この構造体の大きさを知るためには sizeof 演算子を用いる. struct entry の定義が addr.h に書かれているとすると,以下のプログラムはそのバイト数を表示する.
sizeof.c
1 #include <stdio.h>
2 #include "addr.h"
3
4 int main(void)
5 {
6 printf("sizeof(struct entry) = %ld\n", sizeof(struct entry));
7 return 0;
8 }
コンパイル,実行すると,以下のようになる.
$ ./a.out
struct entry は,名前に32バイト配列を2つ,住所とメイルに128バイトの配列を2つ,郵便番号に4バイトの int 型整数を2つ使用しているため,合計328バイトとなり,上記の実行結果と一致する.
構造体の大きさは,必ずしもメンバの大きさの単純な和にはなるとは限らないことに注意 → データファイルのポータビリティ
/var/run/utmp というファイルには,現在ログインしているユーザなどのログイン情報が記録されている. 以下のプログラムは utmp のデータを fread を利用して1エントリごとに読み込み,ログイン情報を表示するプログラムである.
注:下記のプログラムは Linux ではうまくコンパイル,実行できるが,Mac OS X では utmp ファイルが廃止されているため,コンパイルに失敗する.
utmp.c
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <time.h>
4 #include <utmp.h>
5
6 int main(void)
7 {
8 FILE *fp;
9 struct utmp u;
10
11 fp = fopen(_PATH_UTMP, "r");
12
13 if (fp == NULL) {
14 perror(_PATH_UTMP);
15 exit(-1);
16 }
17
18 while (fread(&u, sizeof(u), 1, fp) == 1) {
19 if (u.ut_type != DEAD_PROCESS) {
20 time_t t = u.ut_time;
21 printf("%8.8s|%16.16s|%8.8s|%s", u.ut_name,
22 u.ut_host, u.ut_line, ctime(&t));
23 }
24 }
25
26 fclose(fp);
27
28 return 0;
29 }
struct utmp の定義は /usr/include/utmp.h から読み込まれる. 11行目の _PATH_UTMP は /var/run/utmp を表す. マクロになっているのは UNIX のバージョンによりパスが異なることがあるためであり,マクロを使うことによりプログラムの移植性を高めることができる.
18行目で読み込んだエントリを21~22行目で出力している. printf の出力フォーマットで %8.8s のピリオド(.)の前の8は8桁のフィールド幅を確保することを意味し,またピリオドの後ろの8は出力する最大文字数を表す. すなわち,%8.8s は常に8文字分のフィールドにはみ出さないように出力されることを意味する. utmp ファイルには終了したプロセスのエントリも含まれるため,そのようなエントリは表示しないようにする処理を加えている.
上記のプログラムをコンパイル,実行すると以下のようになる.出力の一部を修正した.出力は各コンピュータごとに異なる. who コマンドはデフォルトでは表示するエントリをかなり絞るが,-a というオプションを与えると,すべてのエントリを表示する.
$ ./a.out
Mac OS X でログイン情報を得るには,getutxent 関数を用いて utmpx ファイルのエントリを順次読み込むことになる. 以下は getutxent を用いたプログラムである. getutxent は内部の固定領域に utmpx ファイルのエントリを読み込むため,再度 getutxent を呼び出すと読み込んだ内容が上書きされることに注意する.
getutxent.c
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <time.h>
4 #include <utmpx.h>
5
6 int main(void)
7 {
8 struct utmpx *up;
9
10 while ((up = getutxent()) != NULL) {
11 if (up->ut_type != DEAD_PROCESS) {
12 printf("%8.8s|%16.16s|%8.8s|%s", up->ut_user,
13 up->ut_host, up->ut_line, ctime(&up->ut_tv.tv_sec));
14 }
15 }
16
17 return 0;
18 }
構造体のデータを書き込んで作成したファイルのデータを様々なコンピュータで共有しようとする時に注意しなければいけないのは,データがどのようにファイルに書かれているのかという点である. すなわち,数値データがどのようにメモリ上で表現されているのかについて知る必要がある. 例えば,以下のような点に気をつける必要がある.
ある意味,最もポータビリティが高いのは1バイトごとにアクセスできるテキストファイルである. 例えば,様々なデータを扱えるように設計された XML はテキスト形式である.
utmp ファイルの各エントリの内容を保持するリストを作ることを考える. 読み込むレコードが固定長ならば,ファイルのサイズから必要な領域のサイズを計算することもできるが,ここではあえてエントリを読み込むたびに必要な領域を動的に確保してみる.
注:下記のプログラムは Linux ではうまくコンパイル,実行できるが,Mac OS X では utmp ファイルが廃止されているため,コンパイルに失敗する.
utmp-list1.c
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <strings.h>
4 #include <time.h>
5 #include <utmp.h>
6
7 struct utmplist {
8 struct utmplist *next;
9 struct utmp u;
10 };
11
12 int main(void)
13 {
14 FILE *fp;
15 struct utmplist *ulhead = NULL;
16 struct utmplist *ulprev, *ulp;
17
18 fp = fopen(_PATH_UTMP, "r");
19 if (fp == NULL) {
20 perror(_PATH_UTMP);
21 exit(-1);
22 }
23
24 for (;;) {
25 ulp = calloc(1, sizeof(struct utmplist));
26 if (ulp == NULL) {
27 perror("calloc");
28 fclose(fp);
29 exit(-1);
30 }
31
32 if (fread(&ulp->u, sizeof(ulp->u), 1, fp) != 1) {
33 free(ulp);
34 break;
35 }
36
37 if (ulhead == NULL)
38 ulhead = ulp;
39 else
40 ulprev->next = ulp;
41
42 ulprev = ulp;
43 }
44
45 fclose(fp);
46 ulp = ulhead;
47
48 while (ulp) {
49 if (ulp->u.ut_type != DEAD_PROCESS) {
50 time_t t = ulp->u.ut_time;
51 printf("%8.8s|%16.16s|%8.8s|%s", ulp->u.ut_name,
52 ulp->u.ut_host, ulp->u.ut_line, ctime(&t));
53 }
54 ulprev = ulp;
55 ulp = ulp->next;
56 free(ulprev);
57 }
58
59 return 0;
60 }
7~10行目でリストを作る構造体を定義している. メンバ next がリストの次の要素へのポインタであり,メンバ u は utmp 構造体である. つまり,構造体の中に構造体を埋め込んでいる. 24~43行目の for ループで,領域を確保し,そこへエントリを読み込み,リストを更新している. 作成したリストは48~57行目で出力している.
上記の utmp ファイルを読み込むプログラムは main 関数が長くなり,やや読みにくい. そこで、読み込み部と書き出し部を関数に分け構造化したプログラムを以下に示す. 関数単位で内容を把握することができ,わかりやすくなる.
注:下記のプログラムは Linux ではうまくコンパイル,実行できるが,Mac OS X では utmp ファイルが廃止されているため,コンパイルに失敗する.
utmp-list2.c
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <strings.h>
4 #include <time.h>
5 #include <utmp.h>
6
7 struct utmplist {
8 struct utmplist *next;
9 struct utmp u;
10 };
11
12 struct utmplist *read_utmp(FILE *fp, struct utmplist *head)
13 {
14 struct utmplist *ulprev, *ulp;
15
16 for (;;) {
17 ulp = calloc(1, sizeof(struct utmplist));
18 if (ulp == NULL) {
19 perror("calloc");
20 fclose(fp);
21 exit(-1);
22 }
23
24 if (fread(&ulp->u, sizeof(ulp->u), 1, fp) != 1) {
25 free(ulp);
26 break;
27 }
28
29 if (head == NULL)
30 head = ulp;
31 else
32 ulprev->next = ulp;
33
34 ulprev = ulp;
35 }
36
37 return head;
38 }
39
40 void write_utmp(FILE *fp, struct utmplist *head)
41 {
42 struct utmplist *ulprev;
43 struct utmplist *ulp = head;
44
45 while (ulp) {
46 if (ulp->u.ut_type != DEAD_PROCESS) {
47 time_t t = ulp->u.ut_time;
48 printf("%8.8s|%16.16s|%8.8s|%s", ulp->u.ut_name,
49 ulp->u.ut_host, ulp->u.ut_line, ctime(&t));
50 }
51 ulprev = ulp;
52 ulp = ulp->next;
53 free(ulprev);
54 }
55 }
56
57 int main(void)
58 {
59 FILE *fp;
60 struct utmplist *ulhead = NULL;
61
62 fp = fopen(_PATH_UTMP, "r");
63 if (fp == NULL) {
64 perror(_PATH_UTMP);
65 exit(-1);
66 }
67
68 ulhead = read_utmp(fp, ulhead);
69
70 fclose(fp);
71
72 write_utmp(stdout, ulhead);
73
74 return 0;
75 }
ファイルの内容にアクセスする方法のうち,これまで見てきた read, write を用いる方法とは全く違った方法として,ファイルをアドレス空間にマップするメモリマッピングまたはメモリマップトファイル (memory mapped file) と呼ばれる方法がある. ファイルをアドレス空間にマップすることで,ファイルの内容を配列のように扱うことができ,配列の添字やポインタを用いてファイルの読み書きをできるようになる.
メモリマッピングを行うためには,mmap システムコールを使用する.
void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset); int munmap(void *addr, size_t length);
mmap はファイルディスクリプタ (fd) で指定されたファイルをアドレス空間にマップする. 引数として,ファイルのどの位置 (offset) からどれだけの長さ (length) をマップするか指定する. また,マップされた領域のメモリ保護の仕方 (prot) とタイプ (flags) も指定する.
munmap は,マップされた領域を解放する.すなわち,領域とファイルとのつながりを消す.
_PATH_UTMP をアクセスするプログラムを,メモリマッピングを用いるように変更すると以下のようになる.
注:下記のプログラムは Linux ではうまくコンパイル,実行できるが,Mac OS X では utmp ファイルが廃止されているため,コンパイルに失敗する.
utmp-mmap.c
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4 #include <time.h>
5 #include <utmp.h>
6 #include <fcntl.h>
7 #include <sys/types.h>
8 #include <sys/stat.h>
9 #include <sys/mman.h>
10
11 int main(void)
12 {
13 int fd, num, err;
14 struct stat fs;
15 struct utmp *u0, *u;
16 size_t maplen;
17
18 fd = open(_PATH_UTMP, O_RDONLY);
19 if (fd < 0) {
20 perror(_PATH_UTMP);
21 exit(-1);
22 }
23
24 if (fstat(fd, &fs) < 0) {
25 perror("fstat");
26 exit(-1);
27 }
28
29 /* The size of a mapped area must be a multiple of pagesize */
30 for (maplen = fs.st_size;
31 maplen % sysconf(_SC_PAGE_SIZE) != 0;
32 maplen++);
33
34 u0 = u = mmap(NULL, maplen, PROT_READ, MAP_PRIVATE, fd, 0);
35 if (u == MAP_FAILED) {
36 perror("mmap");
37 exit(-1);
38 }
39
40 num = fs.st_size / sizeof(struct utmp);
41
42 while (num--) {
43 if (u->ut_type != DEAD_PROCESS) {
44 time_t t = u->ut_time;
45 printf("%8.8s|%16.16s|%8.8s|%s", u->ut_name,
46 u->ut_host, u->ut_line, ctime(&t));
47 }
48 u++;
49 }
50
51 err = munmap(u0, maplen);
52 if (err) {
53 perror("munmap");
54 exit(-1);
55 }
56 close(fd);
57
58 return 0;
59 }
上記のプログラムをコンパイル,実行すると,fread で読み込むプログラムが表示する情報と同じ情報が表示される. 変更点は以下の通りである.
以下は,自分でバッファを確保してのファイルコピーのプログラムの28~34行目を #if 0 ~ #endif で囲み,コンパイル時に無視(正確にはコンパイラのプリプロセッサにより削除)されるようにすることで,malloc による動的メモリ確保が行われないようにしたプログラムである. 7行目で void * 型の変数 buf が宣言されているが,初期化されず,その値は不定のまま,39, 47行目で読み書きのバッファに指定されている. buf は有効なメモリ領域を指していない可能性が高いため,実行するとエラーになる可能性が高い. たとえエラーを出さずに実行できてしまったとしても,どこかの領域を破壊している可能性が高い.
filecopy-buf-bad.c
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 int main(int argc, char *argv[])
5 {
6 FILE *src, *dst;
7 void *buf;
8 int rcount, wcount;
9
10 if (argc != 3) {
11 printf("Usage: %s from_file to_file\n", argv[0]);
12 exit(1);
13 }
14
15 src = fopen(argv[1], "r");
16 if (src == NULL) {
17 perror(argv[1]);
18 exit(1);
19 }
20
21 dst = fopen(argv[2], "w");
22 if (dst == NULL) {
23 perror(argv[2]);
24 fclose(src);
25 exit(1);
26 }
27
28 #if 0
29 buf = malloc(BUFSIZ);
30 if (buf == NULL) {
31 perror("malloc");
32 fclose(src);
33 fclose(dst);
34 exit(1);
35 }
36 #endif
37
38 while (!feof(src)) {
39 rcount = fread(buf, 1, BUFSIZ, src);
40 if (ferror(src)) {
41 perror("fread");
42 fclose(src);
43 fclose(dst);
44 exit(1);
45 }
46
47 wcount = fwrite(buf, 1, rcount, dst);
48 if (ferror(dst)) {
49 perror("fwrite");
50 fprintf(stderr, "tried to write %d bytes, "
51 "but only %d bytes were written.\n",
52 rcount, wcount);
53 fclose(src);
54 fclose(dst);
55 exit(1);
56 }
57 }
58
59 fclose(src);
60 fclose(dst);
61
62 return 0;
63 }
このプログラムはバグを含んでいるがコンパイルできてしまう. しかも,単純に cc コマンドをオプション無しで使用してコンパイルすると,何の警告も出力されないことが多い.
以下のように cc に -Wall というオプションを付けてコンパイルすると,buf が初期化されずに使用されているという警告が出力される. 他にも色々な警告を出力してくれるため,できるだけこのようなオプションを指定すると良い.
$ cc -Wall filecopy-buf-bad.c
変数には,基本的には,グローバル変数とローカル変数があるが,変数名の有効範囲(スコープ)だけでなく,その領域が有効な期間についても理解し,プログラミング時に意識しなければならない. ヒープ領域も加えて,それぞれの領域の有効期間について以下にまとめる.
グローバル変数が使用する領域は,プログラムの実行の開始から終了まで有効である. 確保されているという状態は実行中に変化しないため,静的に確保される領域とも言われる. グローバル変数は初期値を持つ変数と持たない(初期値が0の)変数に区別され,それぞれデータセグメント(セクション),BSS セグメントに置かれる. プログラムの実行開始時に,必要な大きさの領域が確保される. データセグメントのデータはプログラムファイルから読み込まれ,BSS セグメントは0に初期化される. この領域はプログラムの実行が終了するまで解放されることがなく,また解放することもできない. 逆に言うと,実行開始時に必要なメモリが確保できない場合は,プログラムの実行を開始できない. そして,プログラムが領域を使用しているか否かに関わらず,メモリを使用し続けてしまう.
ローカル変数が使用する領域は,その変数が宣言された関数が呼び出されてから呼び出し元に戻るまで有効である.
その関数が別の関数を呼び出した場合も(末尾呼び出しの場合を除き)その関数が return するまで,ローカル変数は有効である.
つまり,関数 func1 で宣言されたローカル変数 var1 は,func1 から呼び出される func2 を実行中も,領域としては有効なままである.
従って,func2 に引数として var1 へのポインタ(&var1)を渡すと,func2 の実行中も var1 の領域は有効であるため,func2 でその領域を使用することができる.
逆に,func1 の戻り値として &var1 を返しても,func1 の return 後にはその領域は無効になるため,その領域を使用した結果は不定となる.
ローカル変数が使用する領域は,スタック上に確保される.
スタックは関数呼び出しの際に伸び,戻る際に縮む.
従って,その領域は繰り返し再利用されることになる.
スタックのための領域の大きさは,システムによって異なる.
プログラムの実行中にスタックのための領域が必要なだけ伸びていくシステムがほとんどだが,スタックのサイズが固定されているシステムもある.
どこまで伸びられるかも,システムや状況によって異なる.
そのため,大きなデータをスタック上に確保する(大きなデータをローカル変数として宣言する)ようなプログラムは,システムにより動作したりしなかったりする可能性がある.
ヒープ領域はプログラム実行開始後,必要な時に確保され不要になったら解放される領域であり,確保から解放まで有効である. 実行中に確保,解放されるため,動的に確保される領域とも言われる. 確保と解放は明示的に行われる. 領域が実行時に確保されるため,確保された領域を指し示す方法はポインタしかない.
ポインタを用いる場合,その指し示す先がどの領域であるかを常に意識し,有効な領域を正しく使用しなければならない.
バッファオーバーフローはプログラムの実行(プロセス)を乗っ取るため,悪意を持った攻撃者によって引き起こされる. バッファオーバーフローにより,攻撃者はプロセスに任意のプログラムを送り込んで実行させたり,任意のデータを送り込んで読み込ませたりすることができてしまい,プロセスは乗っ取られてしまう.
バッファオーバーフローがどうして起こるのか理解するためには,プロセスが実行時に用いられるスタックの構造について理解する必要がある.
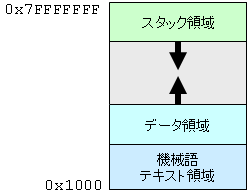
下図は,実行中のプロセスのメモリ空間においてどのようにデータが配置されているかを図示したものである. 通常,最も下位のアドレスに機械語命令が入ったテキスト領域が置かれる. その上にデータ領域が置かれる. データ領域とは別に,関数呼び出し時の戻りアドレス(リターンアドレス)や関数のローカル変数が格納されるスタック領域がある. データ領域はデータ割り当てが起こるたびに上位アドレスに向かって伸びていく. スタック領域は逆に,関数呼び出しが起こるたびに下位アドレスに向かって伸びていく.
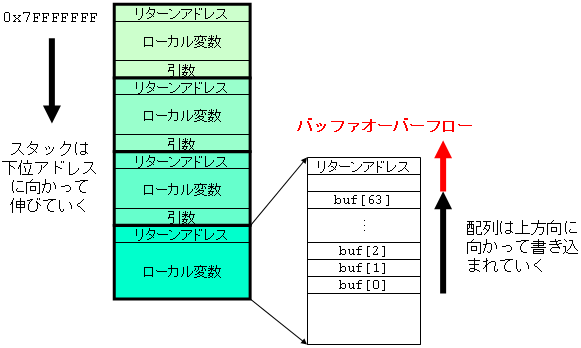
スタック領域をより詳細に図示すると下図のようになる. 関数呼び出しが起こると,リターンアドレスがスタックにプッシュされ,呼び出された関数で使用するローカル変数のための領域が確保される. 関数を呼び出す前には,その関数の引数がスタックにプッシュされる. 呼び出された関数が利用するリターンアドレスやローカル変数などが格納された領域を,スタックフレームと呼ぶ.
スタックフレーム中のローカル変数に配列が含まれていると,配列の添字が小さいほうが下位アドレスにあり,大きいほうが上位アドレスにくる. 上の図で buf がポインタとして例えば fgets に渡されると,buf[0] から上位アドレスに向かって書き込まれていく. ここで fgets の引数に buf のサイズとして誤って 4096 を与えていたとする.すると,ファイルから長い文字列を読み込んだときに,64文字以上の文字が,buf として割り当てられた領域を超えて書き込まれる可能性がある. さらに先まで書き込まれると,リターンアドレスも書き換えられてしまう. 悪意によるプログラムをスタック領域にうまく書き込み,リターンアドレスがあった場所にそのプログラムの開始アドレスを上書きすると,関数が return した後にそのプログラムが実行される. もしくは,悪意によるプログラムを書き込まなくても,リターンアドレスがあった場所にライブラリ関数やプログラム内の関数の開始アドレスを上書きすれば,その関数が実行される.
このような攻撃方法をバッファオーバーフロー攻撃(buffer overflow attacks)やスタックスマッシング (stack smashing) と呼ぶ.
以下はスタックを破壊するプログラムの例である.
bufferoverflow.c
1 #include <stdio.h>
2 #include <string.h>
3
4 char *longstr =
5 "01234567890abcdefghijklmnopqrstuvwxyz"
6 "01234567890abcdefghijklmnopqrstuvwxyz"
7 "01234567890abcdefghijklmnopqrstuvwxyz"
8 "01234567890abcdefghijklmnopqrstuvwxyz"
9 "01234567890abcdefghijklmnopqrstuvwxyz"
10 "01234567890abcdefghijklmnopqrstuvwxyz";
11
12 void with_check(char *src)
13 {
14 char buf[20];
15 int len;
16
17 puts("with_check");
18
19 len = strlcpy(buf, src, sizeof(buf));
20
21 if (len > sizeof(buf) - 1)
22 printf("with_check: buf is too short to copy src(%s).\n",
23 src);
24
25 printf("with_check: buf(%s)\n", buf);
26 }
27
28 void without_check(char *src)
29 {
30 char buf[20];
31 puts("without_check");
32 strcpy(buf, src);
33 printf("without_check: buf(%s)\n", buf);
34 }
35
36 int main(void)
37 {
38 with_check(longstr);
39 without_check(longstr);
40 return 0;
41 }
このプログラムをコンパイルする際にはオプションに -D_FORTIFY_SOURCE=0 -fno-stack-protector を指定する. 最近のコンパイラはバッファオーバーフロー攻撃を防ぐための機構を,生成されるコード中に自動的に組み込むが,これらのオプションを指定すると組み込まなくなる.
このプログラムでは without_check 関数の実行中にスタックが破壊される.このプログラムは without_check 関数から main 関数に戻る際におかしなアドレスに戻ろうとするため,以下のように異常終了してしまう.
$ ./a.out