![[←]](picture/screen-return.gif) abcdefghijklmnopqrstuvwxyz
$
abcdefghijklmnopqrstuvwxyz
$

理解を深めるために
コンピュータは2進数しか扱えないので,文字も数として表す必要がある. ある数値がどの文字にあたるかの対応の決まりを文字コードと呼ぶ. 文字コードには唯一絶対というようなものはなく,場合によって使い分けられている. 欧米では必要となる文字数が少ないため,文字コードも標準的なものがあるが,それ以外(特に日本)は大変複雑になってしまっている.
UNIX で標準的に使われてきたのが ASCII(アスキー)コードである. ASCII は American Standard Code for Information Interchange の略であり,その名のとおりアメリカで使うために作られたものである. 7ビットで表現され,ローマ字,数字,記号,制御コードからなる. 数値との対応は以下の通り:
| 上位3ビット→ ↓下位4ビット |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 0 | NUL | DLE | SP | 0 | @ | P | ` | p |
| 1 | SOH | DC1 | ! | 1 | A | Q | a | q |
| 2 | STX | DC2 | " | 2 | B | R | b | r |
| 3 | ETX | DC3 | # | 3 | C | S | c | s |
| 4 | EOT | DC4 | $ | 4 | D | T | d | t |
| 5 | ENQ | NAC | % | 5 | E | U | e | u |
| 6 | ACK | SYN | & | 6 | F | V | f | v |
| 7 | BEL | ETB | ' | 7 | G | W | g | w |
| 8 | BS | CAN | ( | 8 | H | X | h | x |
| 9 | HT | EM | ) | 9 | I | Y | i | y |
| A | LF/NL | SUB | * | : | J | Z | j | z |
| B | VT | ESC | + | ; | K | [ | k | { |
| C | FF | FS | , | < | L | \ | l | | |
| D | CR | GS | - | = | M | ] | m | } |
| E | SO | RS | . | > | N | ^ | n | ~ |
| F | SI | US | / | ? | O | _ | o | DEL |
|
|
|
|
EUC は Extended UNIX Code の略であり,EUC-JP は UNIX では広く使われている日本語文字コードである. 基本的には漢字1文字を2バイトで表すが,3バイトで表される補助漢字もある.
| 下位4ビット→ ↓上位4ビット |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A0 | 亜 | 唖 | 娃 | 阿 | 哀 | 愛 | 挨 | 姶 | 逢 | 葵 | 茜 | 穐 | 悪 | 握 | 渥 | |
| B0 | 旭 | 葦 | 芦 | 鯵 | 梓 | 圧 | 斡 | 扱 | 宛 | 姐 | 虻 | 飴 | 絢 | 綾 | 鮎 | 或 |
| C0 | 粟 | 袷 | 安 | 庵 | 按 | 暗 | 案 | 闇 | 鞍 | 杏 | 以 | 伊 | 位 | 依 | 偉 | 囲 |
| D0 | 夷 | 委 | 威 | 尉 | 惟 | 意 | 慰 | 易 | 椅 | 為 | 畏 | 異 | 移 | 維 | 緯 | 胃 |
| E0 | 萎 | 衣 | 謂 | 違 | 遺 | 医 | 井 | 亥 | 域 | 育 | 郁 | 磯 | 一 | 壱 | 溢 | 逸 |
| F0 | 稲 | 茨 | 芋 | 鰯 | 允 | 印 | 咽 | 員 | 因 | 姻 | 引 | 飲 | 淫 | 胤 | 蔭 |
上記の表の最初にある「亜」という漢字は1バイト目が B0,2バイト目が A1 となる. EUC-JP では,漢字は1バイト目,2バイト目共に8ビット目が立っている(1である). そのため,ある任意の1バイトを見ただけで漢字であるかどうか判別できるという利点がある. しかし,それが漢字の1バイト目なのか2バイト目なのかはわからない.
以下のバックスラッシュ「\」についての記述は,macOS や Linux にはあてはまりません. それらの OS を使っている場合は,高い可能性で,半角バックスラッシュ「\」は正しく表示されます.
日本語の文字コードでは,ASCII コード 0x5C の文字がバックスラッシュ「\」(このバックスラッシュは全角の文字)ではなく円マーク「\」に対応付けられてしまっている. そのため,その2種類の文字は,同じ文字コード(数値)に対応付けられるが,見た目が違うというややこしいことになっている. 以下の簡単なプログラムのように,C プログラム中に円マーク「\」が出てきたら,バックスラッシュと同じとみなしましょう.
#include <stdio.h>
int main(void)
{
printf("Hello world!\n");
return 0;
}
新城先生による解説を参照してください.
http://www.softlab.cs.tsukuba.ac.jp/~yas/classes/ipe/nitiniti2-enshu-1996/1996-11-18/kanji-code.html
文字コードについて腰をすえて学ぶなら,以下の本を薦めます.
日本語文字コードの取り扱いは煩雑で難しい. そのため,この講義では ASCII コードだけを取り扱うことにする.
C 言語においては,シングルクォーテーション「'」で囲まれたものが文字であり,ダブルクォーテーション「"」で囲まれたものが文字列である. 'A' は文字であり,"A" は文字列である. 見た目の差はわずかかもしれないが,両者は似て非なるものである.
シングルクォーテーション「'」で文字を囲んだデータは char 型の定数であり,その定数の値は ASCII コードにおけるその文字に対応した値になる. 下の (1) と (2) は同じ値を変数 c に代入しており,プログラムの読みやすさ以外に何も違いはない.
char c; c = 'A'; /* (1) */ c = 0x41; /* (2) */
文字は数値であるため,演算や比較の対象になる. 下のプログラムでは,char 型の変数 c を ++ でインクリメント(7行目)したり,<= で文字定数と比較(6行目)している.
char.c
1 #include <stdio.h>
2
3 int main(void)
4 {
5 char c = 'a';
6 while (c <= 'z') {
7 putchar(c++);
8 }
9 putchar('\n');
10 return 0;
11 }
実行結果を以下に示す.
$ ./a.out
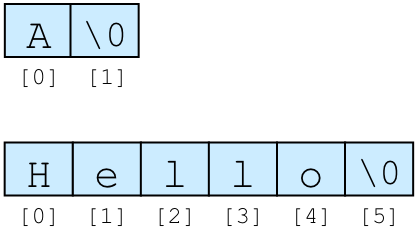
文字は1つの数値であるため,文字の並びである文字列は配列として表される. 文字列の終端を表すために,文字列の最後には 0 が置かれる. 文字列には終端の 0 が含まれるため,文字列の長さは表示される文字数よりも 1 大きくなる. 下の図は "A" および "Hello" という文字列がどのように格納されるか図示したものである.
配列の0番目の要素から順番に文字が入れられ,最後に文字列の終端を表す 0 が入っている. 終端が \0 と書いてあるのは,値が 0 の文字は '\0' と表記するからである.
以下のプログラムは,文字を配列に格納したものが文字列になることを確かめるものである.
string1.c
1 #include <stdio.h>
2
3 char s[] = {'H', 'e', 'l', 'l', 'o', 0};
4
5 int main(void)
6 {
7 int i = 0;
8
9 printf("%s\n", s);
10
11 while (s[i]) {
12 printf("[%d] = %c\n", i, s[i]);
13 i++;
14 }
15
16 return 0;
17 }
3行目では,文字型配列 s に順番に Hello と入るように初期化している. 9行目の printf では変換文字に %s を用いて,文字列を出力している. これで文字型配列 s が文字列となっていることがわかる. 11~14行目では,文字型配列 s の各要素の文字を出力している. C 言語の while では条件式が0でないときに条件が成立しているとみなされるので,s[i] の値が0になるまでこのループの実行は続く. 12行目の printf では変換文字に %c を用いて文字を出力している. これをコンパイル,実行すると以下の結果が得られる.
$ ./a.out
3行目は,以下のように書いても同じである.
string2.c
3 char s[] = "Hello";
しかしながら,以下のプログラムのように書くと,意味が異なってくる.
1 #include <stdio.h>
2
3 char *ps = "Hello";
4
5 int main(void)
6 {
7 int i = 0;
8
9 printf("%s\n", ps);
10
11 while (*ps) {
12 printf("[%d] = %c\n", i, *ps);
13 i++;
14 ps++;
15 }
16
17 return 0;
18 }
上記のプログラムの14行目ではポインタをインクリメントすることにより,次の要素を指すようにしている. 11~15行目の while 文は以下のように書くこともできる. いかにも C らしい簡潔なプログラムになるが,間違いが入りやすいという欠点もある.
string4.c
11 while (*ps) {
12 printf("[%d] = %c\n", i++, *ps++);
13 }
C 言語では標準入出力を用いることで,基本的な入出力を行うことができる. 通常,標準入力はキーボードであり,標準出力は端末画面(ウィンドウ)である. C プログラムを実行しているプロセスは,キーボードからの入力を標準入力から受け取ることができ,また標準出力への出力は端末画面(ウィンドウ)に表示される. さらに,標準エラー出力と呼ばれるもう一つの出力の口がある. 標準エラー出力は,エラーメッセージや警告のメッセージなど例外的な処理に関するメッセージを出力するために使用される. UNIX のシェルは,上記の3つの標準入出力をリダイレクションやパイプによってファイルや他のプログラムに切り替えることができる. 出力先として標準出力と標準エラー出力の2つが存在することの利点はある. 例えば,標準出力をファイルに切り替え,標準エラー出力を端末のままにしておくと,エラーメッセージがファイルではなく端末に出力されるので,エラーの発生にすぐ気づくことができるし,ファイルの中身にエラーメッセージが混ざることもなくなる.
文字,書式で指定されるデータを標準入力から受け取るライブラリ関数として以下のものがある.
int getchar(void); int scanf(const char *format, ...);
また,文字,行,書式で指定される文字列を標準出力に出力するライブラリ関数として以下のものがある.
int putchar(int c); int puts(const char *s); int printf(const char *format, ...);
引数に与えられたファイルポインタに対して入出力を行うライブラリ関数には以下のものがある.
int fgetc(FILE *stream); char *fgets(char *s, int size, FILE *stream); int fscanf(FILE *stream, const char *format, ...); int fputc(int c, FILE *stream); int fputs(const char *s, FILE *stream); int fprintf(FILE *stream, const char *format, ...);
標準入力を表す FILE * 型の定数として,stdin があらかじめ定義されている.また, 標準出力,標準エラー出力を表す FILE * 型の定数として,それぞれ stdout と stderr があらかじめ定義されている. 上の関数宣言の stream と書かれた引数に stdin を与えると標準入力からの読み込みを実現でき,stdout を与えると標準出力への書き込みを実現できる.
以下は getchar により標準入力から1文字読み込み,putchar により標準出力へ1文字書き出すプログラムである. EOF はファイルの終わりを示すデータ(End-Of-File)であり,通常,-1 という値が割り当てられている. getchar が返す値の種類は256よりも大きいため,変数 c を char 型ではなく int 型としていることには大きな意味がある.
getcharputchar.c
1 #include <stdio.h>
2
3 int main(void)
4 {
5 int c;
6
7 while ((c = getchar()) != EOF) {
8 putchar(c);
9 }
10
11 return 0;
12 }
これをコンパイル,実行すると以下のような結果が得られる.端末から読み込まれた文字列がそのまま端末に表示されている. 端末からの入力は,通常,行単位でプログラムに渡される. よって,Enter キーを押すまで,getchar は入力を受け取れず入力を待ち続ける. Ctrl-D の入力は,端末からの入力の終了を伝えるためのものである.
$ ./a.out$
fgetc, fputc を使用すると以下のプログラムのようになる. 結果は,getchar, putchar を使用した場合と,全く同じになる.
fgetcfputc.c
1 #include <stdio.h>
2
3 int main(void)
4 {
5 int c;
6
7 while ((c = fgetc(stdin)) != EOF) {
8 fputc(c, stdout);
9 }
10
11 return 0;
12 }
以下は fgets により標準入力から1行読み込み,puts により標準出力へ1行書き出すプログラムである.
fgetsputs.c
1 #include <stdio.h>
2
3 #define LINE_LEN 80
4
5 int main(void)
6 {
7 char line_buf[LINE_LEN];
8
9 while (fgets(line_buf, LINE_LEN, stdin) != NULL) {
10 puts(line_buf);
11 }
12
13 return 0;
14 }
これをコンパイル,実行すると以下のような結果が得られる.
$ ./a.out
fgets は行末の改行文字(および文字列終端を示す '\0')を含む文字列をバッファに読み込む. そして puts は引数の文字列の後に改行も出力する仕様のため,改行が2回出力されている.
以下のプログラムのように puts の代わりに fputs を使用すると,fputs は単に引数の文字列を出力するだけの仕様のため,改行が2回出力されることはなくなる.
fgetsfputs.c
1 #include <stdio.h>
2
3 #define LINE_LEN 80
4
5 int main(void)
6 {
7 char line_buf[LINE_LEN];
8
9 while (fgets(line_buf, LINE_LEN, stdin) != NULL) {
10 fputs(line_buf, stdout);
11 }
12
13 return 0;
14 }
文字操作のライブラリ関数には,以下の大文字または小文字へ変換する関数と,
int toupper(int c); /* 大文字へ変換 */ int tolower(int c); /* 小文字へ変換 */
以下の文字の種類を判別する関数がある.
int isalnum(int c); /* 英字または数字? */ int isalpha(int c); /* アルファベット? */ int isascii(int c); /* ASCII 文字? */ int isblank(int c); /* 空白文字(スペースまたはタブ)? */ int iscntrl(int c); /* 制御文字? */ int isdigit(int c); /* 数字? */ int isgraph(int c); /* 表示可能文字?(スペースは含まれない) */ int islower(int c); /* アルファベットの小文字? */ int isprint(int c); /* 表示可能文字?(スペースは含まれる) */ int ispunct(int c); /* 表示可能文字?(スペースと英数字は含まれない) */ int isspace(int c); /* 空白文字?(スペース,タブ,改行文字など) */ int isupper(int c); /* アルファベットの大文字? */ int isxdigit(int c); /* 16進数での数字?(0〜9, a〜f, A〜F) */
以下のプログラムは小文字を大文字へ,大文字を小文字へ変換する.
caseconv1.c
1 #include <stdio.h>
2 #include <ctype.h>
3
4 int main(void)
5 {
6 int c;
7
8 while ((c = getchar()) != EOF) {
9 if (islower(c)) {
10 c = toupper(c);
11 } else if (isupper(c)) {
12 c = tolower(c);
13 }
14 putchar(c);
15 }
16
17 return 0;
18 }
これをコンパイル,実行すると以下のような結果が得られる.
$ ./a.out
string のマニュアルに文字列操作のためのライブラリ関数一覧がのっている(man 3 stringで表示可能). 比較的良く使われる関数について解説する.
man 3 string を見ると,関数のリストに加えて,
#include <string.h>
と書かれている. 同じものが,個別の関数のマニュアルページにも書かれている. これは,これらの関数を使用する時には string.h をインクルードしなさいという意味である. 指定されたヘッダファイルをインクルードしないと,エラーによりコンパイルできなかったり,関数が正常に動作しなかったりする.
size_t strlen(const char *s);
strlen は文字列の長さを戻り値として返す. 文字列の終端文字0は文字列の長さには含まれない. よって,strlen("abc") は 3 を返す.
以下のプログラムは,小文字を大文字へ,大文字を小文字へ変換する. ただし,先ほど示したプログラムとは異なり,getchar, putchar ではなく fgets, fputs を用いて行ごとの入出力を行っている. strlen によって文字列の長さを取得して,それをループの終了の判定に用いている.
caseconv2.c
1 #include <stdio.h>
2 #include <ctype.h>
3 #include <string.h>
4
5 #define LINE_LEN 80
6
7 int main(void)
8 {
9 int i, len;
10 char line_buf[LINE_LEN];
11 char *p;
12
13 while (fgets(line_buf, LINE_LEN, stdin) != NULL) {
14 len = strlen(line_buf);
15 p = line_buf;
16 for (i = 0; i < len; i++, p++) {
17 if (islower(*p)) {
18 *p = toupper(*p);
19 } else if (isupper(*p)) {
20 *p = tolower(*p);
21 }
22 }
23 fputs(line_buf, stdout);
24 }
25
26 return 0;
27 }
ループの終了の判定では,文字列の長さを用いるよりも,処理対象の文字が終端文字であるかどうかを検査するほうが,プログラムが速くなる可能性が高い.
int strcmp(const char *s1, const char *s2); int strncmp(const char *s1, const char *s2, size_t n); int strcasecmp(const char *s1, const char *s2); int strncasecmp(const char *s1, const char *s2, size_t n);
これらは2つの文字列 s1 と s2 を比較し,
| 条件 | 戻り値 |
| s1 < s2 | 0より小さい数 |
| s1 == s2 | 0 |
| s1 > s2 | 0より大きい数 |
strncmp, strncasecmp は s1 の先頭 n 文字についてのみ,比較を行う.
strcasecmp, strncasecmp は大文字,小文字を区別せずに(例えば A と a は同じとみなして)比較する.
char *strchr(const char *s, int c); char *strrchr(const char *s, int c); char *index(const char *s, int c); char *rindex(const char *s, int c); char *strstr(const char *haystack, const char *needle);
strchr, index は,文字列 s を先頭から探して最初に c の文字が現れたところへのポインタを返す.
strrchr, rindex は,文字列 s を最後尾から探して最初に c の文字が現れたところへのポインタを返す.
strstr は,文字列 haystack を先頭から探して,最初に needle が見つかったところへのポインタを返す.
どれも,見つからなかった場合は NULL が戻り値になる.
以下のプログラムは,ファイルパスの構成要素を切り出して出力する.
index.c
1 #include <stdio.h>
2 #include <string.h>
3 #include <sys/param.h>
4
5 int main(void)
6 {
7 int i;
8 char line_buf[MAXPATHLEN];
9 char *p, *np;
10
11 while (fgets(line_buf, MAXPATHLEN, stdin) != NULL) {
12 i = 0;
13 p = line_buf;
14 while ((np = index(p, '/')) != NULL) {
15 *np = '\0';
16 printf("%d: %s\n", i++, p);
17 p = np + 1;
18 }
19 printf("%d: %s\n", i, p);
20 }
21
22 return 0;
23 }
8行目の MAXPATHLEN は,システムで定義されているパス名の最大長である. MAXPATHLEN は sys/param.h で定義されている. これをコンパイル,実行すると以下の結果が得られる.
$ ./a.out
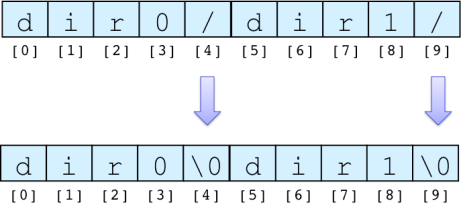
このプログラムは1つの文字列中に含まれる '/' を index を用いて検索し,見つかったら,その文字を '\0' に置き換える. 文字列とは終端文字 '\0' までの文字配列であるため,'/' を '\0' に置き換えることで,1つの文字列を複数の文字列に分割している.
下図では配列の4番目に格納されている '/' を '\0' に置き換えている. これにより,元の配列が表す文字列は "dir0" となる. また,配列の9番目に格納されている '/' を '\0' に置き換えている. これにより,元の配列の5番目の要素を指すポインタの先にある文字列は "dir1" となる.
このように文字列をコピーすることなく,文字列の一部を切り出すことができる(ただし,この切り出し方では,元の文字列も変わることに注意).
size_t strlcpy(char *dst, const char *src, size_t size); size_t strlcat(char *dst, const char *src, size_t size);
注意: これらの関数は情報科学類計算機の macOS 環境では使えるが,Linux 環境では使えない.
strlcpy は src の文字列を dst にコピーする. strlcat は src の文字列を dst の文字列の後ろに(dst の終端文字がある場所から始まる領域に)コピーする. size はコピー先 dst のサイズを表す. strlcpy の引数 size に与える値は,コピー先 dst のバッファのサイズである. strlcat の引数 size に与える値は,コピー先 dst にすでに入っている文字列の長さも含んだバッファのサイズである.
strlcpy, strlcat は,src の文字列を全てコピーできたかどうかに関わらず,コピー先の文字列(dst の文字列)に終端文字0を付ける. 従って,strlcpy は最大 size - 1 文字コピーし,strlcat は最大 size - strlen(dst) - 1 文字コピーする.
strlcpy, strlcat は,それらが作成しようとした文字列の長さを戻り値として返す(実際に作成した文字列の長さではない). すなわち,strlcpy の戻り値は src の文字列の長さ strlen(src) であり,strlcat の戻り値は dst の文字列の長さと src の文字列の長さの和である.
以下は strlcpy, strlcat を使用して文字列のコピーを行う例である. コピー先のバッファの大きさは sizeof 演算子により取得している(sizeof(配列) の値は配列のサイズであるが,sizeof(ポインタ) の値はポインタそのもののサイズであるため,sizeof(ポインタ) はバッファの大きさを得るためには使えないことに注意).
strlcpy.c
1 #include <stdio.h>
2 #include <string.h>
3
4 int main(void)
5 {
6 char buf5[5];
7 char buf20[20];
8 char *s1 = "01234567890";
9 char *s2 = "abcdefghijklmnopqrstuvwxyz";
10 int len;
11
12 len = strlcpy(buf5, s1, sizeof(buf5));
13 printf("copy to buf5: s1=\"%s\", len-s1=%d, str-in-buf=\"%s\", len-str-in-buf=%ld\n",
14 s1, len, buf5, strlen(buf5));
15
16 len = strlcpy(buf20, s1, sizeof(buf20));
17 printf("copy to buf20: s1=\"%s\", len-s1=%d, str-in-buf=\"%s\", len-str-in-buf=%ld\n",
18 s1, len, buf20, strlen(buf20));
19
20 len = strlcat(buf20, s2, sizeof(buf20));
21 printf("cat to buf20: s2=\"%s\", len-s1s2=%d, str-in-buf=\"%s\", len-str-in-buf=%ld\n",
22 s2, len, buf20, strlen(buf20));
23
24 return 0;
25 }
これをコンパイル,実行すると以下のような結果が得られる.
$ ./a.out
dst に用意されているバッファの長さを超えてはコピーされないことがわかる.
strlcpy,strlcat は全ての UNIX で用意されているわけではない. 使用できない場合には以下の関数を使用するしかないが,これらの関数を使うとバッファオーバーフローの脆弱性をより含ませやすくなるため,使用には注意が必要である.
char *strncpy(char *dst, const char *src, size_t n); char *strncat(char *dst, const char *src, size_t n); char *strcpy(char *dst, const char *src); char *strcat(char *dst, const char *src);
strncpy は src の文字列を終端文字0も含めて dst に最大 n 文字コピーする. strncpy は src の文字列が n 文字よりも短かった場合,dst のバッファ内の文字列よりも後ろの部分を0で埋める. strncat は src の文字列を dst の文字列の後ろに(dst の終端文字がある場所から始まる領域に)最大 n 文字コピーし,その後に終端文字0をコピーする.
strncpy,strncat は,コピーした n 文字に終端文字0が含まれるかどうかはチェックしない. strncpy でコピーした n 文字に終端文字0が含まれない場合には,dst のバッファの中身は終端文字で終わらない文字型データの並び(文字列ではないもの)になる. よって,その中身を文字列として printf などによって表示することはできない. strncat は,コピー先のバッファの空き部分の長さが n 文字以下だった場合には,バッファの長さを超えてコピーを行う(バッファオーバーフローを起こす)ことになる.strcpy は src の文字列を終端文字0も含めて dst にコピーする. strcat は src の文字列を dst の文字列の後ろに(dst の終端文字がある場所から始まる領域に)コピーし,最後に終端文字0を追加する.
strncpy, strncat, strcpy, strcat の戻り値は単に dst である. よって,strlcpy, strlcat と異なり,全ての src の文字列がコピーできたのかどうかは戻り値からはわからない.
strcat, strcpy では,コピー先のバッファのサイズを指定できないため,バッファオーバーフローの脆弱性をより含ませやすい.これらの関数の使用はできる限り避けたほうが良い.
printf の仲間の関数である snprintf を用いることによっても文字列のコピーと連結を行うことができる.
int snprintf(char *dst, size_t size, const char *format, ...);
snprintf は printf とほぼ同じように使用できるが,結果は dst に文字列として格納される. size はバッファ dst のサイズである. 終端文字 0 が末尾に追加されるため,最大 size - 1 文字が dst に出力される.
snprintf の戻り値は,もし出力バッファが無限大であった場合に何文字出力されたか(終端文字 0 は含まない)である. 実際に何文字出力されたかではない. すなわち,戻り値と size を比較することにより,十分な大きさのバッファを提供していたかどうかがわかる.
上記の strlcpy, strlcat を使用したプログラムを snprintf を用いて書き直すと以下のようになる.
snprintf.c
1 #include <stdio.h>
2 #include <string.h>
3
4 int main(void)
5 {
6 char buf5[5];
7 char buf20[20];
8 char *s1 = "01234567890";
9 char *s2 = "abcdefghijklmnopqrstuvwxyz";
10 int len;
11
12 len = snprintf(buf5, sizeof(buf5), "%s", s1);
13 printf("copy to buf5: s1=\"%s\", len-s1=%d, str-in-buf=\"%s\", len-str-in-buf=%ld\n",
14 s1, len, buf5, strlen(buf5));
15
16 len = snprintf(buf20, sizeof(buf20), "%s", s1);
17 printf("copy to buf20: s1=\"%s\", len-s1=%d, str-in-buf=\"%s\", len-str-in-buf=%ld\n",
18 s1, len, buf20, strlen(buf20));
19
20 len = snprintf(buf20, sizeof(buf20), "%s%s", s1, s2);
21 printf("cat to buf20: s2=\"%s\", len-s1s2=%d, str-in-buf=\"%s\", len-str-in-buf=%ld\n",
22 s2, len, buf20, strlen(buf20));
23
24 return 0;
25 }
これをコンパイル,実行すると以下のように同じ結果が得られる.
$ ./a.out
snprintf は printf と同じようにフォーマットを指定しての文字列出力ができるため,数値の文字列への変換と文字列の結合などを混在して行えるのが便利である.
char *strdup(const char *s); /* 文字列の複製 */ char *strfry(char *string); /* 文字列のランダム化 */ char *strsep(char **stringp, const char *delim); /* トークンの切り出し */ char *strtok(char *s, const char *delim); /* トークンへの分解 */ size_t strcspn(const char *s, const char *reject); /* 文字セットに含まれない文字数 */ char *strpbrk(const char *s, const char *accept); /* 文字セットに含まれる文字の検索 */ size_t strspn(const char *s, const char *accept); /* 文字セットに含まれる文字数 */ int strcoll(const char *s1, const char *s2); /* ロケールに基づく文字列比較 */ size_t strxfrm(char *dst, const char *src, size_t n); /* ロケールに基づいた文字列変換 */
strdup は関数の内部で動的にメモリ領域を確保することに注意が必要である. strdup で作られた文字列のためのメモリ領域は,使用後に free によって解放する必要がある.
getchar や fgets で数字を入力として受け取っても,受け取った入力はその数字が表す数ではなく文字または文字列である. '1' は文字定数であり,その値は 0x31 であり 1 ではない. "123" という文字列は 0x31, 0x32, 0x33, 0x00 という文字の並びであり,123 という数値とは異なる. 表示通りの数値で計算するためには,文字や文字列を数値に変換する必要がある. 逆に,123という数値はそのままでは表示することができず,表示するためには '1', '2', '3' という文字の並び,または "123" という文字列に変換する必要がある.
以下のライブラリ関数を用いると,文字列を数値に変換することができる. sscanf は scanf と同じバッファオーバーフローの脆弱性を含ませやすいので,使用には注意が必要である.
long int strtol(const char *nptr, char **endptr, int base); unsigned long int strtoul(const char *nptr, char **endptr, int base); double strtod(const char *nptr, char **endptr); long atol(const char *nptr); int atoi(const char *nptr); double atof(const char *nptr); int sscanf(const char *str, const char *format, ...);
数値を文字列に変換するライブラリ関数として sprintf, snprintf が使用できる. sprintf はバッファオーバーフロー脆弱性を非常に含ませやすいため.非常に注意深く使用する必要がある. snprintf では書き出す最大文字数を指定できるので,sprintf に代わって常に snprintf を使用すべきである.
int sprintf(char *str, const char *format, ...); int snprintf(char *str, size_t size, const char *format, ...);
malloc は初期化されていないメモリ領域をヒープ領域内に動的に確保し,そこへのポインタ値を返す. calloc は0に初期化されたメモリ領域をヒープ領域内に動的に確保し,そこへのポインタ値を返す. free は malloc により確保されたメモリ領域を解放する.
#include <stdlib.h> void *malloc(size_t size); void *calloc(size_t count, size_t size); void free(void *ptr);
malloc によって確保されたメモリ領域の内容は不定であり,0に初期化されているわけではない. 一方,calloc により確保されたメモリ領域の内容は0である. また,free は解放するメモリ領域の内容を消去しない.
malloc で確保されたメモリ領域はプログラムのどこでも使用できる. 大域変数のための領域は,コンパイル時にその大きさが決まり,プログラム実行開始時に確保されるが, malloc で確保されるメモリ領域は,malloc が呼び出された時点で,引数で指定された大きさの領域が確保される. 実行状況に基づいて計算した値などを malloc の引数に与えることによって,必要なだけのメモリ領域を確保できる. malloc が呼び出されなければ,そのメモリ領域は確保されない.
上記の strlcpy, strlcat を使用して文字列のコピーを行うプログラムを,配列をローカル変数として宣言するのではなく malloc を用いて確保するように書き直すと以下のようになる.
malloc1.c
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <string.h>
4
5 int main(void)
6 {
7 char *buf5;
8 char *buf20;
9 char *s1 = "01234567890";
10 char *s2 = "abcdefghijklmnopqrstuvwxyz";
11 int len;
12
13 buf5 = malloc(5);
14 if (buf5 == NULL) {
15 perror("malloc");
16 exit(1);
17 }
18
19 buf20 = malloc(20);
20 if (buf20 == NULL) {
21 perror("malloc");
22 exit(1);
23 }
24
25 len = strlcpy(buf5, s1, 5);
26 printf("copy to buf5: s1=\"%s\", len-s1=%d, str-in-buf=\"%s\", len-str-in-buf=%ld\n",
27 s1, len, buf5, strlen(buf5));
28
29 len = strlcpy(buf20, s1, 20);
30 printf("copy to buf20: s1=\"%s\", len-s1=%d, str-in-buf=\"%s\", len-str-in-buf=%ld\n",
31 s1, len, buf20, strlen(buf20));
32
33 len = strlcat(buf20, s2, 20);
34 printf("cat to buf20: s2=\"%s\", len-s1s2=%d, str-in-buf=\"%s\", len-str-in-buf=%ld\n",
35 s2, len, buf20, strlen(buf20));
36
37 free(buf5);
38 free(buf20);
39
40 return 0;
41 }
関数の引数に配列名だけを与えると,その配列の先頭アドレスがその関数に渡される. 関数の引数に配列名だけを与えた場合とポインタ変数を与えた場合とで,プログラムは非常に似通ったものになるが,以下の注意点,相違点がある.
25 len = strlcpy(buf5, s1, sizeof(buf5));
malloc で確保した範囲を超えるメモリ領域にアクセスしてはいけない. ローカル変数や大域変数として確保したメモリ領域へのアクセスと同様に,malloc で確保したメモリ領域へのアクセスにおいても,確保したメモリ領域の範囲内かどうかのチェックは行われない. 確保した範囲を超えてアクセスした場合,確保したサイズや実行状態により,セグメンテーションフォルトが起きることもあり得るし,アクセスできてしまうこともある. アクセスできてしまうと,プログラムが動いたり動かなかったり,データ破壊が起こったり起こらなかったりするため,わかりにくいバグになる. 確保したメモリ領域の範囲内だけを使用するように常に意識する必要がある.
以下は,上記のプログラムの buf20 を buf5 に置き換えるなどの修正を行って,確保したサイズを超えてアクセスした例である. 26, 30行目の buf20 を用いるべき場所で buf5 を用いたことにより,確保したメモリ領域を超えた部分まで文字列をコピーしている. 24行目で bzero により buf20 の内容を0に初期化し,34行目で buf20 の内容を出力している. 初期化から出力までの間,buf20 には全くアクセスしていない.
malloc2.c
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <string.h>
4
5 int main(void)
6 {
7 char *buf5;
8 char *buf20;
9 char *s1 = "01234567890";
10 char *s2 = "abcdefghijklmnopqrstuvwxyz";
11 int len;
12
13 buf5 = malloc(5);
14 if (buf5 == NULL) {
15 perror("malloc");
16 exit(1);
17 }
18
19 buf20 = malloc(20);
20 if (buf20 == NULL) {
21 perror("malloc");
22 exit(1);
23 }
24 bzero(buf20, 20); /* fill the buffer with zero */
25
26 len = strlcpy(buf5, s1, 5);
27 printf("copy to buf5: s1=\"%s\", len-s1=%d, str-in-buf=\"%s\", len-str-in-buf=%ld\n",
28 s1, len, buf5, strlen(buf5));
29
30 len = strlcat(buf5, s2, 20);
31 printf("cat to buf5: s2=\"%s\", len-buf5s2=%d, str-in-buf=\"%s\", len-str-in-buf=%ld\n",
32 s2, len, buf5, strlen(buf5));
33
34 printf("buf20: str-in-buf=\"%s\", len-str-in-buf=%ld\n", buf20, strlen(buf20));
35
36 free(buf5);
37 free(buf20);
38
39 return 0;
40 }
これをコンパイル,実行すると,特に実行時エラーは起こらない. ただし,表示される buf20 の内容は空文字列ではなく,buf5 に書き込んだデータの一部となっており,buf5 に対する strlcat が buf20 の内容までも破壊したことがわかる.
$ ./a.out
malloc で確保したメモリ領域を free した後に,その領域にアクセスすると何が起こるかは不定である. アクセス時にエラーになる場合もあるが,再利用され別のデータを格納するために使用されている場合もある. 解放したメモリ領域へのアクセスは,データの破壊やデータの不正な読み出しなどのわかりにくい問題を引き起こす.
解放後にポインタ変数に NULL を代入しておくことによって,誤ったポインタの使用をある程度は防ぐことができる. 以下の例では,buf5 が参照するメモリ領域を2行目で解放した後,3行目で buf5 に NULL を代入している. 4行目で buf5 が参照するメモリ領域に文字列をコピーしようとすると,実行時に NULL ポインタアクセスのエラーとなる.
1 buf5 = malloc(5);
2 free(buf5);
3 buf5 = NULL;
4 i = strlcpy(buf5, d, 5);
メモリリークとは,確保したメモリ領域を解放しないことにより,その領域を使用しておらず使用する予定もないのに,確保したままになることを指す. メモリリークが繰り返し起きた場合,大量にメモリが浪費された状態になる. 最終的には,メモリ確保ができなくなる. malloc で確保したメモリ領域外にアクセスした場合と同じく,メモリリークが起きた場合にも,プログラムは一見正常に動いているように見えることがある. しかし,長期間動作するプログラムにおいて,月単位,年単位でメモリリークが蓄積された結果メモリ確保ができなくなることもあり,メモリリークは非常に発見が難しいバグである.
以下は,非常に単純なメモリリークを起こすプログラムの例である. 確保した領域へのポインタを12行目で buf に代入し,18~20行目で使用している. この領域を解放しないまま,別の領域へのポインタを22行目で buf に代入してしまっている. その結果,12行目で確保した領域へのポインタが失われ,その領域を解放できなくなっている.
malloc3.c
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <string.h>
4
5 int main(void)
6 {
7 char *buf;
8 char *s1 = "01234567890";
9 char *s2 = "abcdefghijklmnopqrstuvwxyz";
10 int len;
11
12 buf = malloc(5);
13 if (buf == NULL) {
14 perror("malloc");
15 exit(1);
16 }
17
18 len = strlcpy(buf, s1, 5);
19 printf("copy to buf: s1=\"%s\", len-s1=%d, str-in-buf=\"%s\", len-str-in-buf=%ld\n",
20 s1, len, buf, strlen(buf));
21
22 buf = malloc(20);
23 if (buf == NULL) {
24 perror("malloc");
25 exit(1);
26 }
27
28 len = strlcat(buf, s2, 20);
29 printf("cat to buf: s2=\"%s\", len-bufs2=%d, str-in-buf=\"%s\", len-str-in-buf=%ld\n",
30 s2, len, buf, strlen(buf));
31
32 free(buf);
33
34 return 0;
35 }
実行結果は正しく,短時間の実行では問題が発生しないことが,メモリリークの発見を難しくしている.
講義資料の「文字列」の部分で示したstring3.cを変更して文字列定数の内容を書き換えると,セグメンテーションフォルトやバスエラーなどの実行時エラーが発生することを確かめよ.
また,cc のオプションに -fwritable-strings を与えると文字列定数の内容の書き換えが可能になることも確かめよ.
講義資料の「標準入出力」の部分で示した fgets と puts を用いたプログラム fgetsputs.c の LINE_LEN を 5 に変えて,コンパイル,実行すると以下の結果になる. どうしてこのような結果になるのか,その理由を調べよ.
$ ./a.out
引数に与えられた文字列に含まれる単語の数を数えて返り値として返す関数 wc を作成しなさい.単語とは,ホワイトスペース文字(空白、改行、改ページ、タブ)で区切られている長さ1以上の文字列とする.main 関数からいくつかの文字列を引数に与えて wc 関数を呼び出し,wc 関数が正しく動くことを確かめなさい.
たとえば以下のようなテストプログラムを実行して,wc が正しい結果を返すかどうかを確認するとよい.
#include <stdio.h>
#include <ctype.h>
int wc(char *str)
{
...
}
int main(void)
{
char *str;
str = "University of Tsukuba"; // 3
printf("%d\n", wc(str));
str = "Hello\tworld!\nGood-bye\tworld!\n\n"; // 4
printf("%d\n", wc(str));
str = " Ten little Indians standin' in a line;\n"
" One toddled home and then there were nine.\n"
" Nine little Indians swingin' on a gate;\n"
" One tumbled off and then there were eight.\n"; // 30
printf("%d\n", wc(str));
return 0;
}
講義資料の「文字や文字列の検索」の部分で示した index.c は,先頭に / がある場合や末尾が / で終わる場合をうまく扱えず,実行結果は次のようになる.
$ ./a.out
最初の例では先頭の / がパスの構成要素と認識され 0: のところに / が出力されるように,また次の例では末尾の / が無視され 3: が出力されないように,プログラムを変更せよ.
strlcpy, strdup と同じ動作をする関数 my_strlcpy, my_strdup を作成せよ. main 関数から strlcpy と my_strlcpy の組および strdup と my_strdup の組に同じ引数をいくつかの(2つ以上の)パターンで与えて呼び出し,同じ動作をすることを確かめなさい.
作成した関数において,memcpy,memmove,bcopyなどのメモリコピー用ライブラリ関数を使ってはならない.
malloc や strdup などで確保したメモリ領域は必ず free で解放すること. 解放しなくてもプログラムは問題なく動くが,将来にメモリリークを起こすプログラムを書かないようにする習慣づけのために,この科目の課題では必ず解放するようにしてほしい.
strcmp, strcasecmp と同じ動作をする関数 my_strcmp, my_strcasecmp を作成せよ. main 関数から strcmp と my_strcmp の組および strcasecmp と my_strcasecmp の組に同じ引数をいくつかのパターンで与えて呼び出し,同じ動作をすることを確かめなさい.
strlen と同じ動作をする関数 my_strlen1, my_strlen2 を作成せよ. my_strlen1 は単純なプログラムとし,my_strlen2 は工夫されたプログラムとする. my_strlen2 を my_strlen1 よりも20%程度は高速なもの(80%程度以下の実行時間のもの)にしなさい. また,Linux または macOS 付属ライブラリの strlen の実行時間との比較も行いなさい. プログラム部分の実行時間は,その部分の前と後で計時関数(例えば clock 関数や clock_gettime 関数)を呼び出すことによって計測することができる. 有意な差が出るように,1) 少なくとも数 MB 程度の十分に長い文字列を用い,2) その文字列を作成する時間が計測時間に含まれないようにし,3) 同一文字列に対して同じ関数を繰り返し実行すること. my_strlen1 を繰り返し呼び出す部分が少なくとも数秒程度実行されるように,文字列の長さや繰り返しの回数を調節すること.
注意: strlenの結果を使用しないプログラムをコンパイルすると,C言語コンパイラが最適化によってstrlenの処理全体が除去することがある.実験では,strlenの処理が除去されていないかどうか(実行が速すぎないかどうか)に気をつけること.除去されている場合には,strlenの結果を変数に格納したり,端末に表示したりすると良い.
以下のように,シェルのように1行入力を受け取り,コマンド名を表示し,入力のリダイレクション記号「<」があればその記号の後のファイル名を表示し,なければ console と表示するプログラムを作りなさい. 入力行は,コマンド名だけ,または「コマンド名 < ファイル名」(< の前後にスペース1つ)という形式だけであると仮定してよい.
$ ./a.out
メモリリークを起こさないようにする練習として,malloc や strdup などを用いてヒープ領域に確保したメモリ領域は必ず明示的に free すること.
練習問題(208)のプログラムを変更し,出力のリダイレクション記号「>」およびパイプ記号「|」にも対応できるようにせよ. リダイレクション記号の出現順序としては,「<」の後に「>」が現れるパターンにのみ対応すればよい. また,パイプ記号は1つ現れる場合にのみ対応すればよい. パイプ記号が現れる場合は,パイプ記号の前後のそれぞれのコマンドについて,入出力先が表示されるようにする.
練習問題(209)のプログラムを変更し,
上記の全ての要求を満たしていることを示す実行結果をつけること.
入力データの中の空白(ASCIIコード32)をすべてピリオド(ASCIIコード46)に変換し,それを出力データとして出力するプログラムを記述しなさい. プログラムに与えるコマンドライン引数の個数に応じて,データの入力元とデータの出力先としては以下で指定するものを用いなさい.
3個以上のコマンドライン引数を与えた場合や,入力元のファイルや出力先のファイルが開けない場合には,標準エラー出力にエラーメッセージを出力して終了しなさい.