コンピュータサイエンス専攻 追川 修一
理解を深めるために
| 第1週 | |
| 第2週 | |
| 第3週 | |
| 第4週 | |
| 第5週 |
システムプログラムでは,ユーザの立場から計算機システムやオペレーティングシステムをより深く理解し,活用できるようになるためのプログラミングスキルの習得を目的とする.
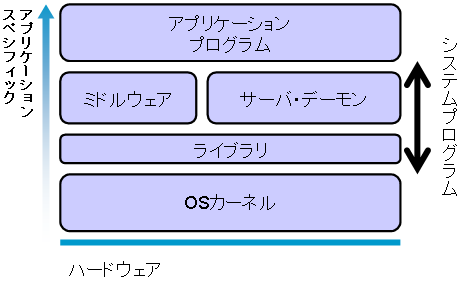
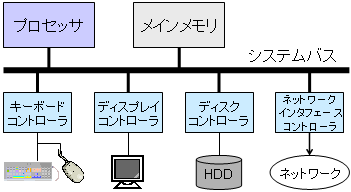
OSはハードウェアの違いを隠蔽し,ユーザがプログラムを実行するための使いやすい環境を提供する. 例えば,PC,ラップトップ,サーバのハードウェア構成(プロセッサの種類や数,メモリの量,入出力デバイスなど)の違いによって,プログラムの変更が必要だとすると,プログラミングが大変である. OSは,ハードウェアを抽象化した概念(アブストラクション)を提供することで,いろいろなコンピュータで共通に使用できる実行環境を提供する.
OSの提供する主な抽象概念としては以下のものがある.
| 抽象概念 | ハードウェア機能 |
| プロセス | プロセッサ,メモリ |
| ファイル,ディレクトリ | ストレージ |
| プロセス間通信 | コンピュータ間の通信 |
| シグナル | 割り込み |
| アクセス制御 | コンピュータ共有時の保護 |
基本的な抽象概念の考え方はめったに変わることはない. 実際,上記の抽象概念は30年以上変わっていない.
OSの「内部の仕組み」については秋学期ABの「オペレーティング・システム I」という講義で扱われる. また,秋学期ABの「分散システム」,秋学期Cの「オペレーティング・システム II 」では,より高度な話題が扱われる. 内部の仕組みの前に,外から見た場合のOSの考え方,使い方を理解することがシステムプログラムの目的である.
OSの提供する抽象概念の集合が,ユーザから見た場合のコンピュータになる. その抽象的なコンピュータを操作するためのインタフェースとしてAPI(Application Program Interface)が提供されている. APIを用いることにより,抽象化されたコンピュータを操作することができるようになる. APIを通して,プログラムという実体のないものが,OS,OSの管理するデバイスを通して,外の世界とつながり,プログラムと人間のインタラクションが可能になる.
APIは一般に
この講義ではUNIX (Mac OS X) を用いて,POSIX (Portable Operating System Interface for UNIX) APIを利用してプログラムを作成する. POSIXはC言語により規定されており,特にシステムコールを直接呼び出す方法は,C言語に対してのみ提供されている. 例えばJavaが文字出力を行うには,最終的にはシステムコールを呼び出すしかない. システムコールを呼び出すプログラムは,Java VMの中でC言語をを用いて書かれている. 従って,この授業の講義・演習で使用するプログラミング言語は,特に断りのない限り,C言語とする.
システムプログラムでは,ライブラリやシステムコールを通してUNIXカーネルを直接的に利用する.
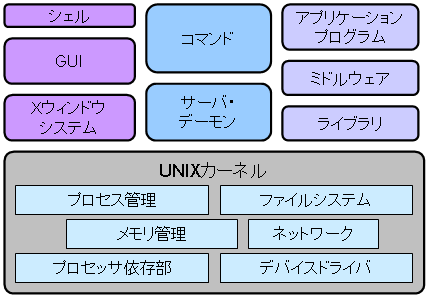
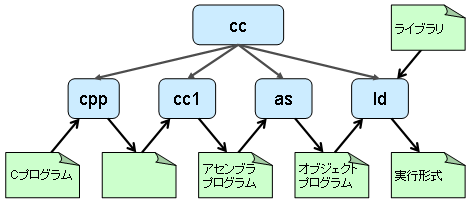
OSという言葉は様々な意味で使われる. 様々なプログラムから構成されるOS環境を意味する場合もあるし,OSカーネルを意味する場合もある. 以下の図は一般的なUNIX環境を構成するプログラムを示している. Mac OS XのネイティブウィンドウシステムはQuartz,またGUIはAquaと呼ばれるものであるが,基本的な全体構成は同じである.
以下,ユーザの目に触れる部分から構成要素について概説する.
UNIXユーザのユーザインタフェースとして最もよく使われるプログラムがシェル(shell)である. シェルは,ユーザの視点からOSを見た場合,OSを操作するためにOSを取り囲んでいる殻という意味である. 一般的なシェルには,BSH(Bourne Shell),BASH(Bourne Again Shell),CSH(C Shell),TCSH(Tenex-like C Shell)などがある.
シェルはCLI(Command Line Interface)を通して,ユーザからのコマンドを受け付け,解釈,実行し,その結果を出力する機能を提供する. シェルは,コマンドの入出力を,ファイルや別のコマンドにするリダイレクションやパイプといった機能を提供する. この機能により,複数の比較的単純な機能を持つコマンドを組み合わせて使用することが可能になる. 実行するコマンドを記述した簡易プログラムとしてシェルスクリプトを作ることもでき,この機能と合わせて,プログラミングの素養を持つユーザには非常に強力なインタフェースを提供している.
情報システム実験 I,IIのシステムプログラムでは,シェルを実際に作成してみる. シェルはUNIXの基本となるプログラムであり,UNIXの基本的な抽象概念の操作が必要であるため,システムプログラムの基本を学習するための題材として最適である.
現在のユーザが直接使用するコンピュータのほとんどはGUIを提供している. Mac OS XやWindowsなどではGUIは完全にOSの一部となってしまっている.
その他の一般的なUNIXではXウィンドウシステムとウィンドウマネージャという独立したプログラムとして提供されている. Xウィンドウシステムは,ビットマップディスプレイ上にウィンドウを表示するための基本的な機能を提供するだけである. ユーザがウィンドウを操作するためのGUIは,GNOMEやKDEといったプログラム群(デスクトップ環境とも呼ばれる)により提供される.
コマンドとは,ユーザが(シェルを通して)コンピュータに与える命令である. UNIXは,シェルから使用することのできる非常に多くのコマンドを提供している. コマンドはシェルとは別のプログラムである場合(外部コマンド)もあるし,シェルに組み込まれている場合(組み込みコマンド)もある. cd, set, umask, exitといったシェル自身の状態を変更するコマンドや,historyなどのシェルが持つ情報を表示するコマンドは組み込みコマンドである. そうでないコマンドは,通常外部コマンドである.
コマンドと呼ぶ場合とアプリケーションと呼ぶ場合に明確な違いがあるわけではない. Officeやビデオ再生プログラムのような,それだけで必要な機能を提供する自己完結的なプログラムをアプリケーションと呼ぶ場合が多い.
UNIXでは,バックグラウンドで動作し様々なサービスを提供する裏方で働くプログラムのことをデーモン(daemon)と呼んでいたが,最近ではサーバと呼ぶことも多い. デーモンには,メイルの配信をするプログラム,プリンタへの出力要求を仲介するプログラム,リモートログインやリモートファイルコピーなどのネットワーク機能を提供するプログラムなどがある.
UNIXでプログラミングをする場合,システムコール,ライブラリ,ミドルウェアを使用してプログラムを作成する. システムコールは,OSカーネルの機能を直接呼び出すためのインタフェースである. UNIXのシステムコールは,できるだけシンプルになるように設計されている. ライブラリとミドルウェアはプログラムの部品となる関数の集合である. ライブラリとミドルウェアの違いは,ライブラリは様々な目的のプログラムで共通の機能を提供するものであるのに対し,ミドルウェアはライブラリより特定のプログラム(例えばGUI)の共通部品となるものである. これらをうまく使うことで,開発効率,信頼性,安全性,移植性が上がり,また出来上がったプログラムも読みやすくなり,実行効率(又は見栄え)も良くなる.
システムコールもライブラリも,Cプログラムから呼び出す場合はどちらも関数呼び出しの形態で使用できるため,同じに見える. UNIXのマニュアルでは,システムコールは2章,ライブラリは3章に分類されており,ヘッダ部分に「READ(2)」のように「(2)」と付いていれば2章の意味でシステムコールであり,「FREAD(3)」のように「(3)」と付いていれば3章の意味でライブラリである.
プログラムとの関係については,プログラム,ライブラリ,システムコールの関係でより詳しく述べる.
UNIXカーネルは,プロセッサの特権モードというハードウェアの全てを制御することのできる動作モードで動作し,直接ハードウェアを制御するプログラムである. UNIXカーネルは,プロセッサの機能を使うことで,複数プログラムの同時実行を可能にし,それぞれのプログラム(又はユーザ)がコンピュータを占有しているかのような幻想を与える. UNIX環境で特権モードで動作するプログラムはカーネルだけである. その他のプログラムは,ユーザモードというハードウェアへのアクセスは制御された環境で動作する.
UNIXカーネルは,大まかに言ってプロセス管理,ファイルシステム,メモリ管理,ネットワーク,プロセッサ依存部,デバイスドライバからなる. ファイルシステム,ネットワークは比較的部品化されているが,全体的にお互いが関係しあって動作する大きなプログラムである.
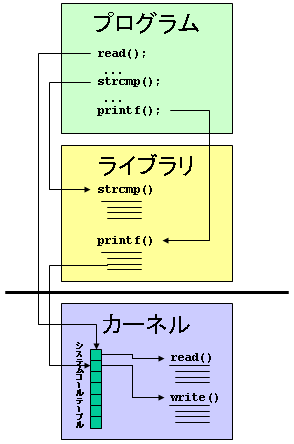
ライブラリ関数とシステムコールは,入出力機能やその他にもいろいろ便利な機能を提供してくれるという点で,プログラマから見ると似ているところがある. しかし,ライブラリ関数とシステムコールには,いくつか大きな違いがある.
上の例では,read はシステムコールなので直接カーネルを呼び出している. strcmp はライブラリだけで機能が実現されているライブラリ関数である. printf はライブラリ関数であるが,標準出力に文字出力を行うために,write システムコールを使用している.
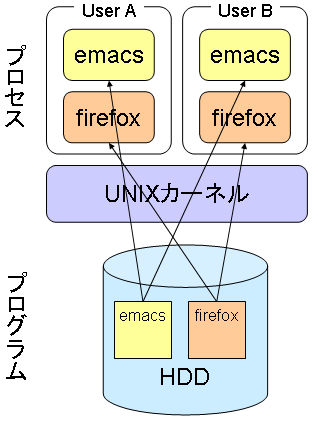
一言で言えば,プログラムを実行中のものがプロセスである. 別の言い方をすると,プログラムはプロセスにより実行される. プログラムとそれを実行中のプロセスは別のものである. 従って,1つのプログラムを複数実行する(同じプロセスを実行しているプロセスを複数作る)ことができる.
プログラムは,CPUが実行できる機械語命令とそれにより処理されるデータの集合(実行形式,ロードモジュール)がファイルに格納されたものである.
つまり,プログラムには何かをするためにCPUで処理を開始するための情報が入っている.
一方,プロセスには実行中の情報が入っている.
実行が進めばデータは書き換えられたり,追加されたりする(機械語命令は通常変わらない).
プログラムには含まれていない,実行中の履歴を格納するためのデータ(スタック)も必要である.
プログラムの実行は通常シェルから行う. シェルのプロンプトにプログラムのファイル名を打ち込むと,そのプログラムを実行するためのプロセスが作られ,実行される. プロセスは誰か(そのプロセス自信でもよい)が終了させないと,いつまでも動いている. 終了させるためには,そのための手順を踏む必要がある(システムコールを呼ぶか強制的に終了させる).
上の例は,HDD (Hard Disk Drive) に格納されている2つのプログラムemacsとfirefoxを異なる二人のユーザが実行している例である. emacs,firefoxのプログラムはそれぞれ1つであるが,同じプログラムを実行して複数のプロセスを作ることができるため,ユーザ毎に別々のプロセスになっている.
UNIXにはプロセスを観察するためのコマンドがいくつか用意されている. psコマンドはプロセスの状態を得るための最も標準的なコマンドであり,全てのUNIXで使用できる. pstree,topコマンドは,用意されていないUNIXシステムもあるかもしれない.
psコマンドはオプションにより様々な情報を表示することができる.
% psPID TT STAT TIME COMMAND 603 p0 Ss 0:00.33 -tcsh 678 p2 Ss+ 0:00.07 -tcsh % ps xu
topはたくさんCPU時間を使用しているプロセスの状態を一定時間おきに表示する.
% top
% man システムコール名
マニュアルを表示するには,他に emacs の中では ESC x man と打ち,モードラインに Manual Entry と表示されたところに表示したいシステムコール,ライブラリ関数,又はコマンド名を打つことで表示することができる.
マニュアルの章立ては以下のようになっている.
| 1章 | コマンド |
| 2章 | システムコール |
| 3章 | ライブラリ関数 |
| 4章 | デバイスファイル |
| 5章 | ファイル形式 |
| 6章 | ゲーム |
| 7章 | その他 |
| 8章 | 管理用コマンド |
man コマンドの引数に指定された名前は,1章から順番に検索される. 従って,man printf とすると1章の printf コマンドのマニュアルが表示されてしまう. ライブラリ関数である printf(3) について知りたいときには,3章であることを指定するために次のように章を指定する.
% man 3 printf
各章の説明用に intro というエントリが用意されている. 2章(システムコール)について知りたいときには,次のようにする.
% man 2 intro
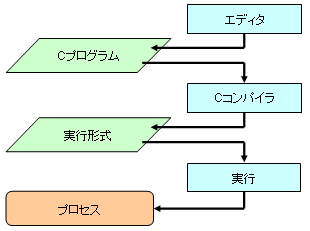
プログラムの作成には,emacs などのエディタでプログラムを作成し,それをCコンパイラ(cc)でコンパイルし,実行を繰り返すことになる. コンパイルでエラーになれば,エディタに戻りプログラムを変更の後,またコンパイル,実行となる. 実行時に間違いが見つかれば,エディタに戻りプログラムを変更の後,またコンパイル,実行となる. プログラムは,いきなり全部を作ろうとするのではなく,部品となる部分を少しずつ動作を確かめながら作るのが良い.
プログラム作成時に気をつけて欲しいことの一つにインデンテーションがある.
エディタとしてEmacsを使用している場合,デフォルトのインデンテーション(字下げ,段付け)のスタイルはあまり一般的ではないものになっているため,.emacs に以下の行を追加する. (追加直後は,変更を有効にするために,emacsを一旦終了後,再び起動する.)
(setq c-default-style "linux")
TABキーを叩くことで,設定された値だけ右にインデント(字下げ)される. TABキーを叩くのは行頭である必要はない.
デフォルトでは以下のようなスタイルになる.
1 void sort(int data[], int count){
2 int i, sw=0, last=1, n=count-1;
3 while(sw!=n){
4 sw = n;
5 for(i=n; i>=last; i--)
6 if(data[i]<data[i-1]){
7 swap_array(data, i, i-1);
8 sw=i;
9 }
10 last=sw+1;
11 }
12 }
変更後は以下のようなスタイルになる. また,変数名や予約語,演算子の前後にスペースを入れ,単語が詰まらないようにした. そして,変数宣言部と実行部分間に空行を入れ,分離している.
1 void
2 sort(int data[], int count)
3 {
4 int i;
5 int sw = 0;
6 int last = 1;
7 int n = count - 1;
8
9 while (sw != n) {
10 sw = n;
11 for (i = n; i >= last; i--)
12 if (data[i] < data[i - 1]) {
13 swap_array(data, i, i - 1);
14 sw = i;
15 }
16 last = sw + 1;
17 }
18 }
タブが8文字と字下げ量が多くなり,ブロックが明確になる. また,空白や空行を使うことで,プログラム内の構造がわかりやすくなる.
また,以下のような点にも注意し,他の人も読みやすく,見た目にも綺麗なプログラムを書くことを心がけること.
以下は,Linuxカーネルのコーディング規約である.
少なくとも,第3章くらいまでは,読むと良いでしょう.
http://linuxjf.osdn.jp/JFdocs/kernel-docs-2.6/CodingStyle.html
エディタとしてEmacsを使用しているか否かに関わらず,前半(第1〜5週)のレポート課題では,上記のように8文字分のタブを字下げに使用したインデンテーションスタイルを使用し,また上記の注意点にも気をつけてプログラムを作成し,提出すること. インデンテーションスタイルが異なっている場合は,再提出にします. また,インデンテーションスタイルが守られていても,プログラムが読みにくい場合は,再提出にします.
以下は,sum.c という1から10までの総和を求める簡単なプログラムをコンパイル実行した例である.
% nl -ba sum.c
cc が warning(警告)のメッセージを出したが,正常に終了している. 警告メッセージは,sum.c ファイルの main 関数の11行目(sum.c:11:の11が11行目という意味)で組み込み関数の printf の暗黙の宣言と非互換になっている,という意味である. warning が出てもコンパイルは正常に終了するが,取り除くべきである.
warning の原因は,printf の宣言がないためである. 従って,warning を取り除くには,printf を宣言を追加すればよい. しかし,ライブラリ関数はその宣言が入っているヘッダファイルが用意されているのが普通である. そのヘッダファイル名は man を見るとわかる.
% man 3 printf
printfの宣言は stdio.h に含まれるので,以下のように #include <stdio.h> を追加する修正をすればよいことになる.
1 #include <stdio.h>
2
3 #define MAX 10
4
5 main()
6 {
7 int i, total;
8
9 total = 0;
10 for (i = 1; i <= MAX; i++)
11 total += i;
12
13 printf("total = %d\n", total);
14 }
cc コマンド自体は実はコンパイルといった処理をしない. コンパイルに必要な処理をしてくれるコマンドを呼び出すだけである.
cc に -v オプションを追加すると,cc から起動されるプログラムの様子がわかる. -v オプションは,cc から起動されるプログラムに指定される引数も全て表示される. そのため,例えばプリプロセッサの引数で指定されるマクロや,リンカに指定されるライブラリなどを知ることもできる.
% cc -v sum.c
cc に -E オプションを追加すると,プリプロセッサ(cpp)だけが起動され,結果は標準出力(stdout)に出される. マクロがうまく展開されない時,typedefがうまく処理されない時など,ヘッダファイルに関係するエラーが起きたときに,プリプロセッサを通した結果を見ると原因がわかることがある.
% cc -E sum.c | nl -ba
cc に -c オプションを追加すると,アセンブラまでが実行され,オブジェクトプログラムが作られる. オブジェクトプログラムのファイル名は,元のCプログラムのファイル名のサフィックス(接尾辞)を o に変えたものになる. 即ち,Cプログラムが sum.c というファイル名の場合は sum.o というファイル名になる.
オブジェクトプログラムを cc の引数に指定すると,cc はサフィックスから引数のファイルがオブジェクトプロプログラムであることを判定し,リンカを起動する.
% cc -c sum.c
上の例では,collect2 というプログラムが起動されている. 下のように,collect2 に明示的に -v オプションを渡してみると,ld が起動されているのがわかる.
% /usr/libexec/gcc/i686-apple-darwin10/4.2.1/collect2 -v -dynamic -arch x86_64 -macosx_version_min 10.6.3 -weak_reference_mismatches non-weak -o a.out -lcrt1.10.6.o -L/usr/lib/gcc/i686-apple-darwin10/4.2.1/x86_64 -L/usr/lib/gcc/i686-apple-darwin10/4.2.1/x86_64 -L/usr/lib/i686-apple-darwin10/4.2.1 -L/usr/lib/gcc/i686-apple-darwin10/4.2.1 -L/usr/lib/gcc/i686-apple-darwin10/4.2.1 -L/usr/lib/gcc/i686-apple-darwin10/4.2.1/../../../i686-apple-darwin10/4.2.1 -L/usr/lib/gcc/i686-apple-darwin10/4.2.1/../../.. sum.o -lSystem -lgcc -lSystem
collect2 version 4.2.1 (Apple Inc. build 5646) (dot 1) (i686 Darwin)
/usr/bin/ld -v -dynamic -arch x86_64 -macosx_version_min 10.6.3 -weak_reference_mismatches non-weak -o a.out -lcrt1.10.6.o -L/usr/lib/gcc/i686-apple-darwin10/4.2.1/x86_64 -L/usr/lib/gcc/i686-apple-darwin10/4.2.1/x86_64 -L/usr/lib/i686-apple-darwin10/4.2.1 -L/usr/lib/gcc/i686-apple-darwin10/4.2.1 -L/usr/lib/gcc/i686-apple-darwin10/4.2.1 -L/usr/lib/gcc/i686-apple-darwin10/4.2.1/../../../i686-apple-darwin10/4.2.1 -L/usr/lib/gcc/i686-apple-darwin10/4.2.1/../../.. sum.o -lSystem -lgcc -lSystem
@(#)PROGRAM:ld PROJECT:ld64-95.2.12
Library search paths:
/usr/lib/gcc/i686-apple-darwin10/4.2.1/x86_64
/usr/lib/gcc/i686-apple-darwin10/4.2.1/x86_64
/usr/lib/i686-apple-darwin10/4.2.1
/usr/lib/gcc/i686-apple-darwin10/4.2.1
/usr/lib/gcc/i686-apple-darwin10/4.2.1
/usr/lib/i686-apple-darwin10/4.2.1
/usr/lib
/usr/lib
/usr/local/lib
Framework search paths:
/Library/Frameworks/
/System/Library/Frameworks/
%
リンクの方法には,動的(ダイナミック)リンクと静的(スタティック)リンクがある. 動的リンクとはライブラリを実行時にリンクする方法である. 一方,静的リンクでは,リンク時に全てのライブラリをリンクした実行形式を作成する. 動的リンクをした実行形式は,(ダイナミックリンク可能な)ライブラリを含まないため,静的リンクされた実行形式よりも小さくなる. また,動的リンクされるライブラリで使用されるメモリ領域は,実行形式間で共有することができるため,メモリ使用量が少ない. しかし,実行時にリンク(未解決シンボルの解消)を行うので,わずかに実行が遅くなる.
動的リンクされた実行形式が使用するライブラリは otool コマンドに -L オプションを付けて実行することで知ることができる.(Linuxでは ldd コマンドを用いる.)
% otool -L a.out
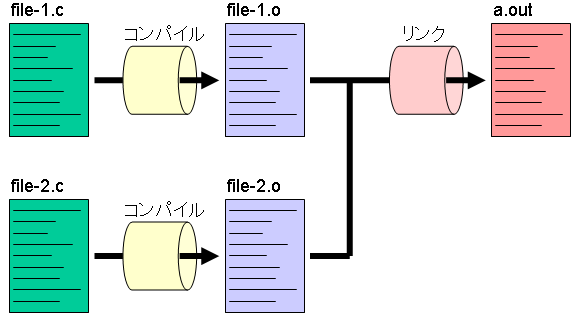
Cプログラムはファイル単位でのシンボルのスコープを持つため,また大きなソースプログラムファイルはコンパイルに時間がかかるため,プログラムは適度に複数ファイルに分割して作成することが望ましい. Cプログラムを複数ファイルに分割した場合,まずそれぞれを cc -c によりオブジェクトプログラムにコンパイルする. そうすると,Cプログラムファイルごとに(サフィックスが o の)オブジェクトプログラムのファイルができる. これらのオブジェクトプログラムのファイルをリンクして実行形式を作る.
このようなコンパイル手順を自動化してくれるのが make コマンドである. make コマンドは,カレントディレクトリにある makefile 又は Makefile を読み込み,そこに書かれているルールに従ってコンパイルを行う(ルールに従って処理をするだけで,処理がコンパイルである必要性は全くない). カレントディレクトリに makefile と Makefile の両方があった場合は,makefile が優先される. 以下は,上の図のコンパイル手順を Makefile として記述したものである.
a.out: file-1.o file-2.o
cc file-1.o file-2.o
file-1.o: file-1.c
cc -c file-1.c
file-2.o: file-2.c
cc -c file-2.c
ルールの書き方の基本的なところは単純で,作成したいターゲットの作成方法を以下のように記述する. 依存ファイルがまた別の依存ファイルから作成される場合(例えば file1.o が file1.cから作成される場合)は,そのためのルールを書く. 依存ファイルがない場合は,必ず処理が実行される.
ターゲット: 依存するファイル <TAB>ターゲット作成のための処理1 <TAB>ターゲット作成のための処理2 ... <TAB>ターゲット作成のための処理n
実際に make コマンドを実行してみると,以下のようになる.
% make
Makefile が複雑になると,Makefile を見ただけでは実際にどのように処理が進むのかすぐにはわからないこともある.そのような場合,make をする前に make -n とすると,実際にコマンドは起動されないが,起動されるコマンドを処理の流れとともに表示してくれる.
デバッガとして gdb が利用できる. 日本語マニュアルは以下に用意されている.
http://www.coins.tsukuba.ac.jp/~syspro/gdb-5.0-doc/
ソースコードを参照しながらデバッガを用いたい場合は cc に -g オプションを付けてコンパイルする必要がある. -g オプションを付けていない場合でも,デバッガを用いることはでき,バックトレース(関数の呼び出し履歴)やアセンブリ言語でどの命令で問題が発生したかはわかる. (stripコマンドでシンボル情報が削除されてしまうと,関数名などグローバルシンボルも表示されなくなる.) -g オプションを付けてコンパイルした場合は,ソースコードの何行目に問題が発生したのかがわかり,また変数名を指定してその値を調べることもできる.
良くあるバグにセグメンテーションフォルト(segmentation fault)やバスエラー(bus error)がある. これらは,アクセスが許可されていない番地などにアクセスすると発生する. 非常に典型的な例としてNULLポインタアクセスがある. 0番地は通常アクセスが許可されていないため,NULLポインタにアクセスするとセグメンテーションフォルトやバスエラーが発生する. Mac OS XではNULLポインタアクセスはバスエラーを起こす. 以下はNULLポインタアクセスによりセグメンテーションフォルトを起こすプログラムを,デバッガから実行した例である.
% cc segfault.c
ある程度の大きさのプログラムをいきなり作成するのは難しい. 問題や設定,条件を単純化し,それを解く小さい簡単なプログラムを作成し,ちゃんと動くようにするところから始める.
例えば,バブル整列法のプログラムを書くことを考えてみる. 最初から,任意個のデータが入ったファイルの内容を整列して出力するプログラムを書こうとするのは(それなりの経験がなければ)賢明とは言えない. 例えば,入力部,整列の部分,出力部に分割し,それぞれの部分が正しく動作するようプログラミングおよびデバッグをしてから,結合するようにすべきである.
整列の部分を作成する時には,整列するデータが必要である. 入力部が完成する前ならば,大域変数に初期値としてデータを与えることが出来る. また,結果を確認するための仮の出力部も必要である. このように,仮の入出力部を用いて作成したバブル整列法のプログラムは以下のようになる(整列の部分は省略).
1 #include <stdio.h>
2
3 #define SAMPLE_COUNT 6
4 int sample[SAMPLE_COUNT] = {8, 12, 3, 15, 7, 4};
5
6 void
7 print_data(int a[], int count)
8 {
9 int i;
10
11 for (i = 0; i < count; i++)
12 printf("%2d ", a[i]);
13 printf("\n");
14 }
15
16 void
17 swap_array(int a[], int i, int j)
18 {
19 int tmp;
20
21 tmp = a[i];
22 a[i] = a[j];
23 a[j] = tmp;
24 }
25
26 void
27 sort(int data[], int count)
28 {
.... omitted ....
35 }
36
37 main()
38 {
39 sort(sample, SAMPLE_COUNT);
40 print_data(sample, SAMPLE_COUNT);
41 }
プログラミングにはデバッグ(バグ取り)が付きものである. 書いたプログラムがそのまま正しく動作することは希であり,何らかの問題により正しく思った通りに動作しないのが普通である. そのため,正しく動作しない原因(バグ)を究明し,取り除く(デバッグ)する必要がある.
多くのオペレーティングシステムではデバッガが用意されているが,最も基本的なデバッグ方法はprintfを用いる方法である. printfを用いることで
上記のバブル整列法のプログラムに以下のsort関数を入れ,
26 void
27 sort(int data[], int count)
28 {
29 int i, j;
30
31 for (i = 0; i < count; i++)
32 for (j = i; j < count; j++)
33 if (data[j] > data[j + 1])
34 swap_array(data, j, j + 1);
35 }
コンパイル実行すると,以下のおかしな結果が出力される.
% ./a.out
そこで,デバッグ用に途中経過を出力するために,32,33行目を追加する.
26 void
27 sort(int data[], int count)
28 {
29 int i, j;
30
31 for (i = 0; i < count; i++) {
32 printf("%d: ", i);
33 print_data(data, count);
34
35 for (j = i; j < count; j++)
36 if (data[j] > data[j + 1])
37 swap_array(data, j, j + 1);
38 }
39 }
コンパイル実行すると,以下ような結果になる.
% ./a.out
情報が足りないので,内側の for 文の中で何が起こっているのか調べることにし,36~38行目,40,41行目,44,45行目を追加する.
26 void
27 sort(int data[], int count)
28 {
29 int i, j;
30
31 for (i = 0; i < count; i++) {
32 printf("%d: ", i);
33 print_data(data, count);
34
35 for (j = i; j < count; j++) {
36 printf("\t[%d]=%d > [%d]=%d",
37 j, data[j], j + 1, data[j + 1]);
38
39 if (data[j] > data[j + 1]) {
40 printf(" ... swap!!");
41
42 swap_array(data, j, j + 1);
43 }
44
45 printf("\n");
46 }
47 }
48 }
コンパイル実行すると,以下ような結果になり,要素数を超えて配列にアクセスしていたことがわかる.
% ./a.out
data[j + 1] までアクセスされるので,for 文の比較判定式では count - 1 した値を使うように変更する.
26 void
27 sort(int data[], int count)
28 {
29 int i, j;
30 int n = count - 1;
31
32 for (i = 0; i < n; i++) {
33 printf("%d: ", i);
34 print_data(data, count);
35
36 for (j = i; j < n; j++) {
37 printf("\t[%d]=%d > [%d]=%d",
38 j, data[j], j + 1, data[j + 1]);
39
40 if (data[j] > data[j + 1]) {
41 printf(" ... swap!!");
42
43 swap_array(data, j, j + 1);
44 }
45
46 printf("\n");
47 }
48 }
49 }
コンパイル実行すると,以下ような結果になる. 配列要素の添字は配列の大きさの範囲内におさまっているが,整列されていない.
% ./a.out
このままでは途中経過が見にくいので,上で追加した内側の for 文の中でのデバッグ出力をコメントアウトし,コンパイル実行すると,以下ような結果になる.
% ./a.out
一番大きい15は最初の外側のループで最後尾まで移動されているが,先頭の8はそのままであることから,内側のループに問題があると考えられる. 内側のループは,最初は data[0] ~ data[5] を,次は data[1] ~ data[5] を比較交換している. これでは先頭の8は最初の外側のループでしか比較交換されない. また,一番大きい15は最初の外側のループで最後尾まで移動されるので,最初は data[0] ~ data[5] を,その次は data[0] ~ data[4] を比較交換しなければいけなかった. そこで,36行目の内側の for 文を以下のように修正する.
26 void
27 sort(int data[], int count)
28 {
29 int i, j;
30 int n = count - 1;
31
32 for (i = 0; i < n; i++) {
33 printf("%d: ", i);
34 print_data(data, count);
35
36 for (j = 0; j < n - i; j++) {
37 // printf("\t[%d]=%d > [%d]=%d",
38 // j, data[j], j + 1, data[j + 1]);
39
40 if (data[j] > data[j + 1]) {
41 // printf(" ... swap!!");
42
43 swap_array(data, j, j + 1);
44 }
45
46 // printf("\n");
47 }
48 }
49 }
コンパイル実行すると,以下ような結果になり,正しく整列できるようになったことがわかる.
% ./a.out
以上のように,printfデバッグでは,最初は大きなブロックの経過を見るようにprintfを入れ,どの部分に問題がありそうかを予測する. 次に,問題がありそうな部分により細かくprintfを入れていく. 細かい原因がわかり修正できたら,細かい結果は出力しないようにすると,全体での途中経過がわかりやすくなる.
デバッグの基本は,実際に確かめもせずに「ここは大丈夫」と思わないこと. 「思い込み」はデバッグの天敵である.
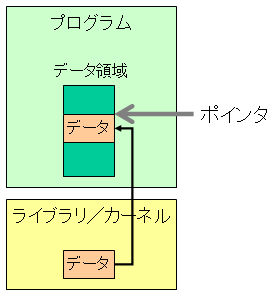
システムプログラムで用いるライブラリ関数やシステムコールにはポインタが必須である. 関数を呼び出し,まとまったデータをやり取りするためにはポインタを使う必要があるからである.
例えば下図のように,あるプログラムがライブラリ又はカーネルを呼び出し,データを読み込もうとしているとする. プログラムは,データを読み込むデータ領域を予め確保し,そこにデータを読み込みたい. そのデータを読み込ませたいデータ領域の先頭を,ライブラリ又はカーネルに知らせる方法がポインタである. ポインタの実態はアドレス(番地)である. ライブラリ又はカーネルはアドレスを受け取り,そこからデータを書き込みはじめる.
他に文字列操作にもポインタは不可欠であるため,ポインタをよく理解しておく必要がある.
アドレス演算子 & をすでに宣言されている変数の前に付けることで,その変数の値を格納するために割り当てられた領域のアドレスが得られる. このアドレスのことをポインタ値という.
間接参照演算子 * は,ポインタ値が指す領域の値を取り出す. 領域に付けられた名前(変数名)ではなく,ポインタ値を用いて参照するので間接参照という.
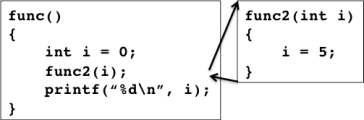
下図ではint型の変数 i, j と,intへのポインタ型変数 p, q が宣言されている. i, j, p, q はそれぞれ別の変数であり,それぞれ別の領域が割り当てられる.
i は1000番地に置かれているものとすると,&i の値は 1000 となり,p に &i を代入すると 1000 が入る. i には 5 が代入されたとすると,*p の値は 5 になる. 図中にはないが,p に &i が代入された状態のまま,*p に 50 を代入すると i の値は 50 になる.
ポインタ値はある変数(領域)を参照する値である. 値であるので,別の関数にポインタ値を渡すことができる. 渡された方の関数は,ポインタ値により参照される変数の値を変更することができる.
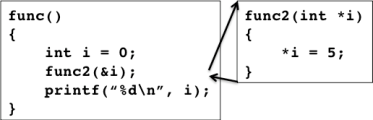
下図は,関数 func のローカル変数 i を引数として別の関数 func2 を呼び出している. func2 では引数 i に 5 を代入しているが,func の i と func2 の i は別の変数であるので,func2 で代入した値は func の i には反映されない. 従って,func2 呼び出し後に i の値を出力した結果は 0 のままである.
一方,下図では,関数 func のローカル変数 i のポインタ値を引数として別の関数 func2 を呼び出している. func2 では引数に間接参照演算子を付けた *i に 5 を代入している. この場合,func2 における *i は func の i を参照しているため,func2 で代入した値は func の i には反映される. 従って,func2 呼び出し後に i の値を出力した結果は 5 になる.
ポインタ変数を初期化せずに,即ち,適切な値(ポインタ値)を入れずに参照してはいけない.
1 func()
2 {
3 int *p;
4
5 *p = 5;
間違ったアドレスに書いてしまう又は書こうとするといろいろ問題が発生する. 書き込めないアドレスに書こうとすると,セグメンテーションフォルトが発生し,プログラムは異常終了する. この場合は,異常終了により間違ったことが起きていることがすぐにわかるので,まだましな場合である.
書き込めるデータ領域だが,意図とは違う間違ったアドレスに書き込まれてしまうと,書き込み自体は成功してしまい,プログラムの実行が進んでから問題が起こる. すると,どうしてここに変なデータが書き込まれているのかと悩むことになる.
これをうまく使ったのがバッファオーバフローである. 外部からスタック上に確保されているバッファよりも多くのデータ(プログラム)を読み込ませることにより,プログラムの実行を乗っ取ってしまう. バッファオーバフローについては第3回目の講義でもう少し詳しく説明する.
関数間でポインタ値を受け渡しをする時には,ポインタ値が参照する変数がどこで宣言(領域確保)されているのか,注意する必要がある. 大域変数やヒープ領域(mallocして確保した領域)は,プログラム中どこでも有効であるので問題はない. しかし,ローカル変数については注意が必要である. ローカル変数は,それを宣言した関数から return する前までの間だけ有効である. そのため,ローカル変数へのポインタ値を戻り値にしてはいけない.
以下のプログラムでは,main関数は関数 badfunc を呼び出しポインタ値を戻り値として受け取っている. ポインタ値を戻り値として受け取ること自体には全く問題はない. しかし,badfunc で返しているポインタ値の参照先が badfunc のローカル変数なのが大きな問題である.
1 #include <stdio.h>
2
3 int *
4 badfunc()
5 {
6 int i = 5;
7
8 return &i;
9 }
10
11 main()
12 {
13 int *i = badfunc();
14
15 printf("1: %d\n", *i);
16 printf("2: %d\n", *i);
17 }
コンパイル実行すると,以下ような結果になる. badfunc を呼び出した後の関数呼び出し(以下のプログラムではprintfの呼び出し)により,badfunc のローカル変数の値は破壊されてしまっていることがわかる. コンパイラは,ローカル変数を戻り値としていることに warning を出している. コンパイラの warning を無視すべきではなく,その原因を究明し,コンパイル時に warning が出ないように修正すべきである.
% cc pointer-4.c
上記のプログラムは,例えば malloc を使用してヒープ領域に確保することで,破壊されることはなくなる. (mallocについてはポインタ(2)で詳述.) しかし,ヒープ領域に確保する malloc(およびその派生関数であるcalloc, valloc)を使用する場合は,確保した領域が不要になった時に必ず free する必要がある. free せずに確保した領域のポインタ値を失ってしまうと,メモリリークという問題が発生する.
4 int *
5 goodfunc()
6 {
7 int *i = malloc(sizeof(int));
8
9 *i = 5;
10
11 return i;
12 }
ポインタ型変数を複数宣言するときには,それぞれの変数名の前に * を付ける.
1 func()
2 {
3 int *p, *q;
ポインタは非常に便利でありシステムプログラミングには欠かせないが,細心の注意をもって使用しないといけない.
コンピュータは2進数しか扱えないので,文字も数として表す必要がある. ある数値がどの文字にあたるかの対応の決まりを文字コードと呼ぶ. 文字コードには唯一絶対というようなものはなく,場合によって使い分けられている. 欧米では必要となる文字数が少ないため,文字コードも標準的なものがあるが,それ以外(特に日本)は大変複雑になってしまっている.
UNIXで標準的に使われてきたのがASCII(アスキー)コードである. ASCII は American Standard Code for Information Interchange の略であり,その名のとおりアメリカで使うために作られたものである. 7ビットで表現され,ローマ字,数字,記号,制御コードからなる. 数値との対応は以下の通り:
| 上位3ビット→ ↓下位4ビット |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 0 | NUL | DLE | SP | 0 | @ | P | ` | p |
| 1 | SOH | DC1 | ! | 1 | A | Q | a | q |
| 2 | STX | DC2 | " | 2 | B | R | b | r |
| 3 | ETX | DC3 | # | 3 | C | S | c | s |
| 4 | EOT | DC4 | $ | 4 | D | T | d | t |
| 5 | ENQ | NAC | % | 5 | E | U | e | u |
| 6 | ACK | SYN | & | 6 | F | V | f | v |
| 7 | BEL | ETB | ' | 7 | G | W | g | w |
| 8 | BS | CAN | ( | 8 | H | X | h | x |
| 9 | HT | EM | ) | 9 | I | Y | i | y |
| A | LF/NL | SUB | * | : | J | Z | j | z |
| B | VT | ESC | + | ; | K | [ | k | { |
| C | FF | FS | , | < | L | \ | l | | |
| D | CR | GS | - | = | M | ] | m | } |
| E | SO | RS | . | > | N | ^ | n | ~ |
| F | SI | US | / | ? | O | _ | o | DEL |
EUC は Extended UNIX Code の略であるように,EUC-JPはUNIXでは広く使われている日本語文字コードである. 基本的には漢字1文字を2バイトで表すが,3バイトで表される補助漢字もある.
| 下位4ビット→ ↓上位4ビット |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A0 | 亜 | 唖 | 娃 | 阿 | 哀 | 愛 | 挨 | 姶 | 逢 | 葵 | 茜 | 穐 | 悪 | 握 | 渥 | |
| B0 | 旭 | 葦 | 芦 | 鯵 | 梓 | 圧 | 斡 | 扱 | 宛 | 姐 | 虻 | 飴 | 絢 | 綾 | 鮎 | 或 |
| C0 | 粟 | 袷 | 安 | 庵 | 按 | 暗 | 案 | 闇 | 鞍 | 杏 | 以 | 伊 | 位 | 依 | 偉 | 囲 |
| D0 | 夷 | 委 | 威 | 尉 | 惟 | 意 | 慰 | 易 | 椅 | 為 | 畏 | 異 | 移 | 維 | 緯 | 胃 |
| E0 | 萎 | 衣 | 謂 | 違 | 遺 | 医 | 井 | 亥 | 域 | 育 | 郁 | 磯 | 一 | 壱 | 溢 | 逸 |
| F0 | 稲 | 茨 | 芋 | 鰯 | 允 | 印 | 咽 | 員 | 因 | 姻 | 引 | 飲 | 淫 | 胤 | 蔭 |
上記の表の最初にある「亜」という漢字は1バイト目が B0,2バイト目が A1となる. EUC-JPでは,漢字は1バイト目,2バイト目共に8ビット目が立っている(1である). そのため,ある任意の1バイトを見ただけで漢字であるかどうか判別できるという利点がある. しかし,それが漢字の1バイト目なのか2バイト目なのかはわからない.
以下のバックスラッシュ「\」についての記述は,Mac OS X にはあてはまりません. Mac OS X を使っている場合は,半角バックスラッシュ「\」は正しく表示されます.
日本語の文字コードでは,ASCIIコードに相当するアルファベット及び記号部分のバックスラッシュ「\」(このバックスラッシュは全角の文字)が円マーク「\」にあてられてしまっている. そのため,文字コード(数値)としては同じ値であるが,目に見える文字としては違うというややこしいことになっている. 例えば以下の簡単なプログラムのように,Cプログラム中に円マーク「\」が出てきたら,バックスラッシュと同じとみなしましょう.
#include <stdio.h>
main()
{
printf("hello world!\n");
}
新城先生が書かれた解説を参照してください.
http://www.hlla.is.tsukuba.ac.jp/~yas/classes/ipe/nitiniti2-enshu-1996/1996-11-18/kanji-code.html
日本語文字コードの取り扱いは煩雑で難しい. そのためシステムプログラムでは,ASCIIコードだけを取り扱うことにする.
文字はシングルクォーテーション「'」で囲まれており,文字列はダブルクォーテーション「"」で囲まれている. 'A' は文字であり,"A" は文字列である. 見た目の差はわずかかもしれないが,両者は似て非なるものである.
シングルクォーテーション「'」で囲まれた文字は char 型の定数であり,値はASCII コードにおける文字に対応した値になる. 下の (1) と (2) は同じ値を変数 c に代入しており,プログラムの読みやすさ以外,意味的にも何ら変わりはない.
char c; c = 'A'; /* (1) */ c = 0x41; /* (2) */
文字は数値であるため,演算や比較の対象になる. 下のプログラムでは,char 型の変数 c を ++ でインクリメント(7行目)したり,<= で文字定数と比較(6行目)している.
1 #include <stdio.h>
2
3 main()
4 {
5 char c = 'a';
6 while (c <= 'z')
7 putchar(c++);
8 putchar('\n');
9 }
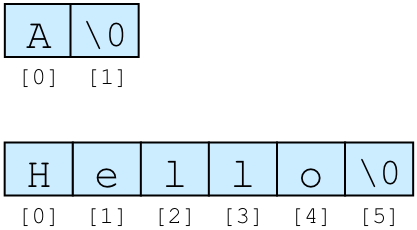
文字は1つの数値であるため,文字の並びである文字列は配列として表される. 文字列の終端を表すために,文字列の最後には 0 が置かれる. 文字列には終端の 0 が含まれるため,文字列の長さは表示される文字数よりも 1 大きくなる. 下の図は "A" および "Hello" という文字列がどのように格納されるか図示したものである.
配列の0番目の要素から順番に文字が入れられ,最後に文字列の終端を表す 0 が入っている. 終端が \0 と書いてあるのは,値が 0 の文字は '\0' と表記するからである.
以下のプログラムは,文字を配列に格納したものが文字列になることを確かめるものである.
1 #include <stdio.h>
2
3 char s[] = {'H', 'e', 'l', 'l', 'o', 0};
4
5 main()
6 {
7 int i = 0;
8
9 printf("%s\n", s);
10
11 while (s[i]) {
12 printf("[%d] = %c\n", i, s[i]);
13 i++;
14 }
15 }
3行目では,文字型配列 s に順番に Hello と入るように初期化している. 9行目の printf では変換文字に %s を用いて,文字列を出力している. これで文字型配列 s が文字列となっていることがわかる. 11〜14行目では,文字型配列 s の各要素の文字を出力している. 12行目の printf では変換文字に %c を用いて,文字を出力している. これをコンパイル実行すると以下のような結果が得られる.
% ./a.out
3行目は,以下のように書いても同じである.
3 char s[] = "Hello";
しかしながら,以下のプログラムのように書くと,意味が異なってくる. 3行目では,char ポインタ型の変数 ps に文字列が代入されて初期化されている. 上記の文字型配列 s は,初期値となる文字列と終端文字 '\0' がぴったり入る大きさの配列となる. 配列の中の個々の文字は変更できるが,s 自体は同じメモリ位置を指し変更できない. 一方,char ポインタ型の変数 ps は文字列定数を指すように初期化されたポインタである. 従って,プログラム中でこのポインタを他の場所を指すように変更することができる. 逆に,文字列定数の内容の変更の結果は(言語仕様上は)不定である. Mac OS X ではバスエラー,Linuxではセグメンテーションフォルトが発生し,プログラムは異常終了してしまうが,できてしまうOSもある.
1 #include <stdio.h>
2
3 char *ps = "Hello";
4
5 main()
6 {
7 int i = 0;
8
9 printf("%s\n", ps);
10
11 while (*ps) {
12 printf("[%d] = %c\n", i, *ps);
13 i++;
14 ps++;
15 }
16 }
上記プログラム14行目ではポインタをインクリメントすることにより,次の要素を指すようにしている.
上記プログラム11〜15行目の while 文は以下のように書くこともできる. いかにもCらしいプログラムになるが,while 中に繰り返す文を追加する場合に,間違いが入りやすいという欠点もある(このように書くべきではないという意味ではない).
11 while (*ps)
12 printf("[%d] = %c\n", i++, *ps++);
C言語では標準入出力を用いることで,基本的な入出力を行うことができる. 通常,標準入力はキーボードであり,標準出力は端末画面(ウィンドウ)である. Cプログラムを実行したプロセスは,キーボードからの入力を標準入力から受け取ることができ,また標準出力への出力は端末画面(ウィンドウ)に表示される. UNIXのシェルは,標準入出力をリダイレクションやパイプによってファイルや他のプログラムに切り替えることができる. この機能により,ファイルアクセスなしに様々な入出力が可能になっている.
標準入力から,文字,行,書式付の入力を行うライブラリ関数として以下のものがある.
int getchar(void); char * gets(char *s); int scanf(const char *format, ...);
また標準出力に対し,文字,行,書式付の出力を行うライブラリ関数として以下のものがある.
int putchar(int c); int puts(const char *s); int printf(const char *format, ...);
これらのうち gets は,後の講義で述べるバッファオーバーフローの原因となる脆弱性を持つため,使用するべきではない.
gets の代わりには,入力バッファの大きさを指定できる fgets を使用すべきである.
scanf も,%s のような書式指定を用いると,バッファオーバーフローに対する脆弱性を持つ.
fgetsに対応する文字,行,書式付きの入出力を行うライブラリ関数には以下のものがある.
int fgetc(FILE *stream); char * fgets(char *s, int size, FILE *stream); int fscanf(FILE *stream, const char *format, ...); int fputc(int c, FILE *stream); int fputs(const char *s, FILE *stream); int fprintf(FILE *stream, const char *format, ...);
stream に stdin と書くと標準入力になり,stdout と書くと標準出力になる. つまり fgetc, fgets では stdin,fputc, fputs, fprintf では stdout を指定する.
標準入出力には,標準出力である stdout の他に,標準エラー出力と呼ばれるもう一つ出力の口がある. 標準エラー出力は stream に stderr と書くことで指定できる. 標準エラー出力は,エラーメッセージや警告のメッセージなど例外的な処理に関するメッセージを出力するために使用される.
以下は getchar により標準入力から1文字読み込み,putchar により標準出力へ1文字書き出すプログラムである.
1 #include <stdio.h>
2
3 main()
4 {
5 int c;
6
7 while ((c = getchar()) != EOF)
8 putchar(c);
9 }
これをコンパイル実行すると以下のような結果が得られる.
% ./a.out%
fgetc, fputc を使用すると以下のプログラムのようになる. 結果は,getchar, putchar を使用した場合と,全く同じになる.
1 #include <stdio.h>
2
3 main()
4 {
5 int c;
6
7 while ((c = fgetc(stdin)) != EOF)
8 fputc(c, stdout);
9 }
以下は fgets により標準入力から1行読み込み,puts により標準出力へ1行書き出すプログラムである.
1 #include <stdio.h>
2
3 #define LINE_LEN 80
4
5 main()
6 {
7 char line_buf[LINE_LEN];
8
9 while (fgets(line_buf, LINE_LEN, stdin) != NULL)
10 puts(line_buf);
11 }
これをコンパイル実行すると以下のような結果が得られる.
% ./a.out
fgets は改行文字もバッファに読み込む. そして puts が文字列を出力した後に改行も出力する仕様のため,改行が2回出力されてしまい,余計な空行が出てしまう. 使用するべきではない gets は行末の改行文字をバッファに読み込まないため,このような問題は生じなかった(しかし1行の文字数がバッファの大きさを越えてしまうと,もっと大きな問題が生じてしまう).
以下のプログラムように puts の代わりに fputs を使用すると,fputs は単にバッファ内の文字列を書き出すだけの仕様のため,上記の問題はなくなる.
1 #include <stdio.h>
2
3 #define LINE_LEN 5
4
5 main()
6 {
7 char line_buf[LINE_LEN];
8
9 while (fgets(line_buf, LINE_LEN, stdin) != NULL)
10 fputs(line_buf, stdout);
11 }
文字操作のライブラリ関数には,以下の大文字又は小文字へ変換する関数と,
int toupper (int c); /* 大文字へ変換 */ int tolower (int c); /* 小文字へ変換 */
以下の文字の種類を判別する関数がある.
int isalnum (int c); /* 英字又は数字? */ int isalpha (int c); /* アルファベット? */ int isascii (int c); /* アスキー文字? */ int isblank (int c); /* 空白文字(スペース又はタブ)? */ int iscntrl (int c); /* 制御文字? */ int isdigit (int c); /* 数字? */ int isgraph (int c); /* 表示可能?(スペースは含まれない) */ int islower (int c); /* 小文字? */ int isprint (int c); /* 表示可能?(スペースを含む) */ int ispunct (int c); /* 表示可能?(スペースと英数字を除く) */ int isspace (int c); /* 空白文字?(スペース,タブ,改行文字など) */ int isupper (int c); /* 大文字? */ int isxdigit (int c); /* 16進数での数字?(0〜9, a〜f, A〜F) */
以下のプログラムは小文字を大文字へ,大文字は小文字へ変換する.
1 #include <stdio.h>
2 #include <ctype.h>
3
4 main()
5 {
6 int c;
7
8 while ((c = getchar()) != EOF) {
9 if (islower(c))
10 c = toupper(c);
11 else if (isupper(c))
12 c = tolower(c);
13 putchar(c);
14 }
15 }
これをコンパイル実行すると以下のような結果が得られる.
% ./a.out
string(3) に文字列操作のためのライブラリ関数一覧がのっている(man 3 stringで表示可能). 比較的良く使われる関数について解説する.
man 3 string を見ると,関数のリストに含まれて
#include <string.h>
とでている. 同じことは,個別の関数のマニュアルページにもでている. これは,これらの関数を使用する時には string.h をインクルードしなさいという意味である. 指定されたヘッダファイルをインクルードしないと,エラーによりコンパイルできない場合,又は関数が正常に動作しない場合がある.
size_t strlen(const char *s);
strlen は文字列の長さを戻り値として返す. 文字列の終端文字 0 は,文字列の長さには含まれない. そのため,strlen("abc") は 3 を返す.
以下のプログラムは,
getchar, putchar を用いた小文字を大文字へ,大文字は小文字へ変換するプログラムを,fgets, fputs を用いて行ごとの入出力にすると,文字列に対し,大文字,小文字の変換をするようになる.
文字列に含まれる文字を先頭から見ていくためには,文字列の長さが必要になるため,strlen を使用する.
1 #include <stdio.h>
2 #include <ctype.h>
3 #include <string.h>
4
5 #define LINE_LEN 80
6
7 main()
8 {
9 int i, len;
10 char line_buf[LINE_LEN];
11 char *p;
12
13 while (fgets(line_buf, LINE_LEN, stdin) != NULL) {
14 len = strlen(line_buf);
15 p = line_buf;
16 for (i = 0; i < len; i++, p++) {
17 if (islower(*p))
18 *p = toupper(*p);
19 else if (isupper(*p))
20 *p = tolower(*p);
21 }
22 fputs(line_buf, stdout);
23 }
24 }
実際は,終端文字であるかどうか検査しながら文字の変換をした方がプログラムとしては速い.
int strcmp(const char *s1, const char *s2); int strncmp(const char *s1, const char *s2, size_t n); int strcasecmp(const char *s1, const char *s2); int strncasecmp(const char *s1, const char *s2, size_t n);
これらは2つの文字列 s1 と s2 を比較し,
| 条件 | 戻り値 | ||
| s1 | s2 | 0より小さい数 | |
| s1 | s2 | 0 | |
| s1 | s2 | 0より大きい数 | |
strncmp, strncasecmp は s1 の先頭 n 文字についてのみ,比較を行う.
strcasecmp, strncasecmp は大文字,小文字を区別せずに(例えば A と a は同じとみなして)比較する.
char * strchr(const char *s, int c); char * strrchr(const char *s, int c); char * index(const char *s, int c); char * rindex(const char *s, int c); char * strstr(const char *haystack, const char *needle);
strchr, index は,文字列 s を先頭から探して最初に c の文字が現れたところへのポインタを返す.
strrchr, rindex は,文字列 s を最後尾から探して最初に c の文字が現れたところへのポインタを返す.
strstr は,文字列 haystack を先頭から探して,最初に needle が見つかったところへのポインタを返す.
どれも,見つからなかった場合は NULL が戻り値になる.
以下のプログラムは,ファイルへのパスの構成要素を切り出して出力する.
1 #include <stdio.h>
2 #include <string.h>
3 #include <sys/param.h>
4
5 main()
6 {
7 int i;
8 char line_buf[MAXPATHLEN];
9 char *p, *np;
10
11 while (fgets(line_buf, MAXPATHLEN, stdin) != NULL) {
12 i = 0;
13 p = line_buf;
14 while ((np = index(p, '/')) != NULL) {
15 *np = '\0';
16 printf("%d: %s\n", i++, p);
17 p = np + 1;
18 }
19 printf("%d: %s\n", i, p);
20 }
21 }
8行目の MAXPATHLEN は,システムで定義されているパス名の最大長である. MAXPATHLEN は sys/param.h で定義されている. これをコンパイル実行すると以下のような結果が得られる.
% ./a.out
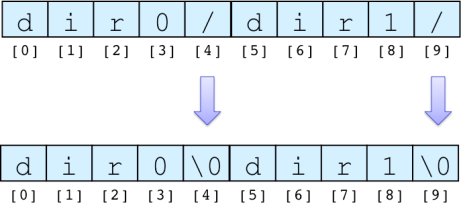
このプログラムは1つの文字列中に含まれる '/' をindexを用いて検索し,見つかったら,その文字を '\0' に置き換える. 文字列とは終端文字 '\0' までの文字配列であるため,'/' を '\0' に置き換えることで,1つの文字列を複数の文字列に分割している.
下図では配列の [4] に格納されている '/' を '\0' に置き換えることにより,[0] から指定される文字列は "dir0" となる.
このように文字列をコピーすることなく,文字列の一部を切り出すことができる.
size_t strlcpy(char *dst, const char *src, size_t size); size_t strlcat(char *dst, const char *src, size_t size);
strlcpy は src の文字列を dst にコピーする. strlcat は src の文字列を dst の文字列の後ろに(dst の終端文字のところから)コピーする. size はコピー先 dst のサイズを表す. strlcpy の場合 dst はコピー先のバッファのサイズであるが, strlcat の場合 dst はすでに入っている文字列の長さも含んだバッファのサイズである.
strlcpy, strlcat は,src の文字列を全てコピーできたかどうかに関わらず,dst の文字列に終端の 0 を付ける. 従って,strlcpy は最大 size - 1 文字コピーし,strlcat は最大 size - strlen(dst) - 1 文字コピーする.
strlcpy, strlcat は,それらが作成しようとした文字列の長さを戻り値として返す. 即ち,strlcpy の場合,それは src の長さ(strlen(src))であり,strlcatの場合 dst と src の長さの和である.
以下は strlcpy, strlcat を使用して文字列のコピーを行う例である. コピー先のバッファの大きさは sizeof 演算子により取得している. (sizeof(配列)の値は配列のサイズであるが,sizeof(ポインタ)はポインタの大きさになってしまうため,バッファの大きさを得るためには使えないことに注意.)
1 #include <stdio.h>
2 #include <string.h>
3
4 main()
5 {
6 char buf5[5];
7 char buf20[20];
8 char *d = "01234567890";
9 char *s = "abcdefghijklmnopqrstuvwxyz";
10 int i;
11
12 i = strlcpy(buf5, d, sizeof(buf5));
13 printf("cpy 5: src(%s) len(%d) dst(%s) len(%d)\n",
14 d, i, buf5, strlen(buf5));
15
16 i = strlcpy(buf20, d, sizeof(buf20));
17 printf("cpy 20: src(%s) len(%d) dst(%s) len(%d)\n",
18 d, i, buf20, strlen(buf20));
19
20 i = strlcat(buf20, s, sizeof(buf20));
21 printf("cat 20: dst(%s) len(%d)\n", buf20, strlen(buf20));
22 }
これをコンパイル実行すると以下のような結果が得られる.
% ./a.out
dst に用意されているバッファの長さを超えてコピーされていないことがわかる.
strlcpy,strlcat は全てのUNIXで用意されているわけではない. 使用できない場合は,以下の関数を使用するしかないが,バッファオーバーフローに対する脆弱性を持つため,使用には注意が必要である.
char * strncpy(char *dst, const char *src, size_t n); char * strncat(char *dst, const char *src, size_t n); char * strcpy(char *dst, const char *src); char * strcat(char *dst, const char *src);
strncpy は src の文字列を終端文字 0 も含めて dst に最大 n 文字コピーする. strncat は,src の文字列を dst の文字列の後に(dst の終端文字のところから)終端文字 0 も含めて最大 n 文字コピーする. strncpy,strncat は,コピーした n 文字に終端文字 0 が含まれるかどうかはチェックしない. しかし,src の文字列が n 文字よりも短かった場合,dst の残りの部分は 0 で埋める.
strcpy は src の文字列を終端文字 0 も含めて dst にコピーする. strcat は src の文字列を dst の文字列の後に(dst の終端文字のところから)コピーし,最後に終端文字 0 を追加する.
strncpy, strncat, strcpy, strcat の戻り値は単に dst である. strlcpy, strlcat と異なり,全ての src の文字列がコピーできたのかどうかは,戻り値からは不明である.
strcat, strcpy は,コピー先の大きさを指定できないため,バッファオーバーフローに対する脆弱性を持つため,使用すべきではない.
printf の仲間の関数である snprintf を用いることでも文字列のコピー,連結を行うことができる.
int snprintf(char *dst, size_t size, const char *format, ...);
snprintf は printf とほぼ同じように使用できるが,結果は dst に文字列として格納される. size はバッファ dst のサイズである. 終端文字 0 が末尾に追加されるため,最大 size - 1 文字が dst に出力される.
snprintf 戻り値は,もし出力バッファが無限大であった場合に何文字出力されたか(終端文字 0 は含まない)である. 即ち,戻り値と size を比較することにより,十分な大きさのバッファを提供しているかどうかがわかる.
上記の strlcpy, strlcat を使用したプログラムを snprintf を用いて書き直すと以下のようになる. 20行目の文字列の結合が,もとになる文字列からコピーしているところだけが異なる.
1 #include <stdio.h>
2 #include <string.h>
3
4 main()
5 {
6 char buf5[5];
7 char buf20[20];
8 char *d = "01234567890";
9 char *s = "abcdefghijklmnopqrstuvwxyz";
10 int i;
11
12 i = snprintf(buf5, sizeof(buf5), "%s", d);
13 printf("cpy 5: src(%s) len(%d) dst(%s) len(%d)\n",
14 d, i, buf5, strlen(buf5));
15
16 i = snprintf(buf20, sizeof(buf20), "%s", d);
17 printf("cpy 20: src(%s) len(%d) dst(%s) len(%d)\n",
18 d, i, buf20, strlen(buf20));
19
20 i = snprintf(buf20, sizeof(buf20), "%s%s", d, s);
21 printf("cat 20: dst(%s) len(%d)\n", buf20, strlen(buf20));
22 }
これをコンパイル実行すると以下のように同じ結果が得られる.
% ./a.out
snprintf は printf と同じようにフォーマットができるため,数値の文字列への変換と文字列の結合などを混在して行えるのが便利である.
char * strdup(const char *s); /* 文字列の複製 */ char * strfry(char *string); /* 文字列のランダム化 */ char * strsep(char **stringp, const char *delim); /* トークンの切り出し */ char * strtok(char *s, const char *delim); /* トークンへの分解 */ size_t strcspn(const char *s, const char *reject); /* 文字セットに含まれない文字数 */ char * strpbrk(const char *s, const char *accept); /* 文字セットに含まれる文字の検索 */ size_t strspn(const char *s, const char *accept); /* 文字セットに含まれる文字数 */ int strcoll(const char *s1, const char *s2); /* ロケールに基づく文字列比較 */ size_t strxfrm(char *dst, const char *src, size_t n); /* ロケールに基づいた文字列変換 */
getcharやfgetsで数字を入力として受け取っても,それは文字または文字列としての入力である. '1' は文字定数であり,その値は 0x31 であり 1 ではない. "123" という文字列は 0x31, 0x32, 0x33 という文字の並びであり,123 という数値とは異なる. 表示通りの数値の値で計算するためには,そのように変換する必要がある. また 123 という数値はそのままでは表示することができず,表示するためには '1', '2', '3' という文字の並び,又は "123" という文字列に変換する必要がある.
以下は文字列を数値に変換してくれるライブラリ関数である. sscanf は scanf と同じバッファオーバーフローに対する脆弱性を持つので,使用には注意が必要である.
long int strtol(const char *nptr, char **endptr, int base); unsigned long int strtoul(const char *nptr, char **endptr, int base); double strtod(const char *nptr, char **endptr); long atol(const char *nptr); int atoi(const char *nptr); double atof(const char *nptr); int sscanf(const char *str, const char *format, ...);
数値を文字列に変換するライブラリ関数として sprintf, snprintf が使用できる. sprintf は,非常に注意深く使用しなければ,バッファオーバーフローを起こす危険がある. snprintf は書き出す最大文字数を指定できるので,sprintf に代わって常に snprintf を使用すべきである. しかし snprintf も snprintf は sprintf を呼び出しているだけのことがあり,安全ではないことがあるので注意が必要である.
int sprintf(char *str, const char *format, ...); int snprintf(char *str, size_t size, const char *format, ...);
malloc はヒープ領域に動的に初期化されていないメモリを確保し,そこへのポインタ値を返す. calloc は0に初期化されたメモリを確保し,そこへのポインタ値を返す. free は malloc により確保されたメモリを解放する.
#include <stdlib.h> void *malloc(size_t size); void *calloc(size_t count, size_t size); void free(void *ptr);
malloc により確保されたメモリの内容は不定であり,0 に初期化されているわけではない. 一方,calloc により確保されたメモリの内容は 0 である. また,free は解放するメモリの内容を消去しない.
malloc で確保されたメモリ領域は,そのポインタ値を,関数の引数,戻り値,大域変数などから得ることが出来れば,プログラム中のどこでも使用できる. 大域変数のための領域は,コンパイル時にその大きさが決まり,プログラム実行開始時に確保されるが, malloc で確保されるメモリ領域は,実行中に malloc が呼び出された時点で,引数で指定された大きさの領域が確保される. malloc への引数には,実行中の状況から計算により求めた値を指定することで,必要なだけのメモリを確保できる. 条件により malloc が呼ばれなければ,そのメモリ領域は確保されない.
strlcpy, strlcat を使用して文字列のコピーを行うプログラムを,ローカル変数で配列を宣言するのではなく,malloc を用いて書き直すと以下のようになる. 配列名だけを指定する場合と,ポインタ変数はほぼ同じように使用できるため,非常に似通ったプログラムになるが,以下の注意点,相違点がある.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <string.h>
4
5 main()
6 {
7 char *buf5;
8 char *buf20;
9 char *d = "01234567890";
10 char *s = "abcdefghijklmnopqrstuvwxyz";
11 int i;
12
13 buf5 = malloc(5);
14 if (buf5 == NULL) {
15 perror("malloc");
16 exit(1);
17 }
18
19 buf20 = malloc(20);
20 if (buf20 == NULL) {
21 perror("malloc");
22 exit(1);
23 }
24
25 i = strlcpy(buf5, d, 5);
26 printf("cpy 5: src(%s) len(%d) dst(%s) len(%d)\n",
27 d, i, buf5, strlen(buf5));
28
29 i = strlcpy(buf20, d, 20);
30 printf("cpy 20: src(%s) len(%d) dst(%s) len(%d)\n",
31 d, i, buf20, strlen(buf20));
32
33 i = strlcat(buf20, s, 20);
34 printf("cat 20: dst(%s) len(%d)\n", buf20, strlen(buf20));
35
36 free(buf5);
37 free(buf20);
38 }
配列は sizeof 演算子でその配列の大きさを取得できるが,ポインタ型変数に sizeof 演算子を用いた場合,その変数の大きさになってしまうことに注意する. 従って,strlcpy, strlcat に渡すコピー先のバッファの大きさは malloc で指定した大きさを書く必要がある(25,29行目). 以下のようにポインタ型変数に sizeof 演算子を使用しても,確保しようとする(または確保した)領域の大きさにはならない.
13 buf5 = malloc(sizeof(buf5));
25 i = strlcpy(buf5, d, sizeof(buf5));
malloc で確保したメモリは,確保したサイズだけ使用する. C言語では配列のインデックス(添字)が宣言された配列のサイズの範囲に収まっているかチェックしないのと同じように,malloc で確保したメモリが確保された範囲内で使用されているかどうかのチェックもしない. 確保したサイズを超えてアクセスした場合,確保したサイズや実行時の状態により,セグメンテーションフォルトが起きることもあり得るし,アクセスできてしまうこともある.
以下は,上記のプログラムのbuf20をbuf5に置き換えて,確保したサイズを超えてアクセスした例である. 25, 29行目で,buf20を用いるべきところをbuf5に書き込んでおり,確保したサイズ以上に書き込んでいる. buf20の方は,23行目で bzero により内容を0に初期化し,buf5に確保したサイズ以上に書き込んだ結果どうなるか,32行目で出力してチェックしている.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <string.h>
4
5 main()
6 {
7 char *buf5, *buf20;
8 char *d = "01234567890";
9 char *s = "abcdefghijklmnopqrstuvwxyz";
10 int i;
11
12 buf5 = malloc(5);
13 if (buf5 == NULL) {
14 perror("malloc");
15 exit(1);
16 }
17
18 buf20 = malloc(20);
19 if (buf5 == NULL) {
20 perror("malloc");
21 exit(1);
22 }
23 bzero(buf20, 20);
24
25 i = strlcpy(buf5, d, 20);
26 printf("cpy 20: src(%s) len(%d) dst(%s) len(%d)\n",
27 d, i, buf5, strlen(buf5));
28
29 i = strlcat(buf5, s, 20);
30 printf("cat 20: dst(%s) len(%d)\n", buf5, strlen(buf5));
31
32 printf("buf 20: dst(%s) len(%d)\n", buf20, strlen(buf20));
33
34 free(buf5);
35 free(buf20);
36 }
これをコンパイル実行すると,特に実行時エラーは起こらない. 32行目でbuf20の内容を表示しているが,そこに確保したサイズを超えて書き込んだデータの一部が表示されており,buf20を破壊していることがわかる.
% ./a.out
アクセスできてしまうと,動いたり動かなかったり,またデータ破壊が起こったり起こらなかったりするため,わかりにくいバグになるため注意が必要である. 確保したサイズだけ使用するするように常に意識して使用する必要がある.
malloc で確保したメモリを free した後は,そのメモリにアクセスすると何が起こるかは不定である. アクセス時にエラーになる場合もあるが,再利用され別の箇所で使用されていることもあるので,その場合はデータ破壊を起こし,わかりにくい問題を引き起こす.
解放後にポインタ変数にNULLを代入しておくことで,ある程度は誤ったポインタの使用を防ぐことができる. 以下の例では,2行目でbuf5が参照するメモリを解放後,3行目でbuf5にNULLを代入する. 4行目にbuf5の参照先にコピーしようとすると,実行時にNULLポインタアクセスのエラーとなる.
1 buf5 = malloc(5);
2 free(buf5);
3 buf5 = NULL;
4 i = strlcpy(buf5, d, 5);
しかし,以下の例のように,別の関数 func_to_free で free が呼ばれ解放されてしまうような場合,func_to_free で free 後に上記のようにNULLを代入していても,呼び出しもとではそれは無意味なため注意が必要である.
1 buf5 = malloc(5);
2 func_to_free(buf5); // free(buf5);
3 i = strlcpy(buf5, d, 5);
メモリリークとは,確保したメモリの解放を忘れ,使用しておらず使用する予定もないのに,確保したままになっている状態を指す. メモリリークが繰り返し起きた場合,大量にメモリが浪費された状態になる. 最終的には,メモリ確保ができなくなる. メモリリークも,上記の問題と同じく,プログラムは一見正常に動いているように見えてしまう. しかし,長期間動作するプログラムで,月単位,年単位で問題が蓄積された結果起こることもあり,非常に発見が難しいバグである. そのため,常に気をつけてプログラミングをする必要がある.
以下は,非常に単純なメモリリークを起こすプログラムの例である. 12行目で確保した領域へのポインタをbufに入れ,18~20行目で使用している. この領域を開放せずに,22行目で同じ変数に別に確保した領域へのポインタを入れてしまっている. こうすると,12行目で確保した領域へのポインタが失われてしまい,解放することができなくなってしまう.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <string.h>
4
5 main()
6 {
7 char *buf;
8 char *d = "01234567890";
9 char *s = "abcdefghijklmnopqrstuvwxyz";
10 int i;
11
12 buf = malloc(5);
13 if (buf == NULL) {
14 perror("malloc");
15 exit(1);
16 }
17
18 i = strlcpy(buf, d, 5);
19 printf("cpy 5: src(%s) len(%d) dst(%s) len(%d)\n",
20 d, i, buf, strlen(buf));
21
22 buf = malloc(20);
23 if (buf == NULL) {
24 perror("malloc");
25 exit(1);
26 }
27
28 i = strlcpy(buf, d, 20);
29 printf("cpy 20: src(%s) len(%d) dst(%s) len(%d)\n",
30 d, i, buf, strlen(buf));
31
32 free(buf);
33 }
実行結果は正しく,短時間の実行では問題が発生しないことが,メモリリークの発見を難しくしている.
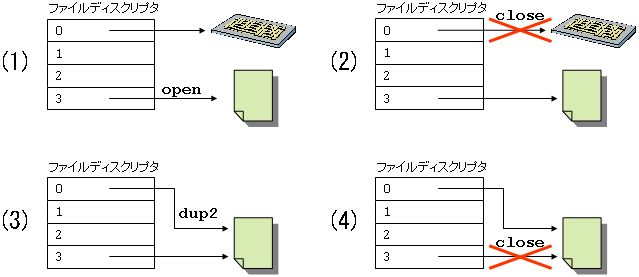
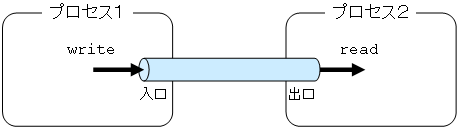
ファイルアクセスをする方法には,システムコールを用いる方法と,ライブラリ関数を用いる方法がある. どちらにせよ手順は同じで,アクセスしたいファイルを開き (open) ,読み書き (read, write) を行い,最後に閉じる (close).
ライブラリを用いてファイルアクセスを行うために,ファイルを開き,閉じるためには fopen, fclose を用いる. 読み書きのためには,実は標準入出力で述べた関数のうち,先頭に f がついている関数が使用できる. 引数で指定できる FILE *stream を,stdin, stdout の代わりに,fopen の戻り値として得られる値にすればよい. ファイルからの入出力に便利なように fread, fwrite という関数も用意されている(これらも標準入出力で用いることができる).
FILE * fopen(const char *path, const char *mode); int fclose(FILE *stream); size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream); size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
ファイルを開くために使用する fopen の戻り値の型は FILE * (FILE構造体へのポインタ)である. 1文字入力の fgetc は,読み込み先として引数に FILE * 型の変数を指定し,1文字出力の fputc は引数に文字の他に書き込み先として FILE * 型の変数を指定する.
つまり,ライブラリを用いてファイルアクセスを行うためには,FILE構造体へのポインタ(通称,ファイルポインタ)が,ファイルの代理人のようなものになる.
FILE構造体には,読み書きしているファイル,ファイルに対し許される操作(読み込み,書き込み,又は両方),現在ファイルのどの部分をアクセスしているのか,エラーは起きていないか,などの情報を持つ. ファイルポインタは,このデータ構造体へのポインタになっており,入出力にあたってファイルポインタを指定することで,読み書きを行うことができるようになっている.
fgetc, fputc を用いて標準入力から読み込み,標準出力へ書き出すプログラムは,fopen, fclose を前後に入れることで,簡単にファイルのコピーを行うプログラムになる.
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 main()
5 {
6 int c;
7 FILE *src, *dst;
8
9 src = fopen("src", "r");
10 if (src == NULL) {
11 perror("src");
12 exit(1);
13 }
14
15 dst = fopen("dst", "w");
16 if (dst == NULL) {
17 perror("dst");
18 fclose(src);
19 exit(1);
20 }
21
22 while ((c = fgetc(src)) != EOF)
23 fputc(c, dst);
24
25 fclose(src);
26 fclose(dst);
27 }
2行目の stdlib.h は,12行目,19行目の exit の宣言を含む.
8行目の fopen では,読込元のファイルとして "src" ,オープン時のモードとして "r" を指定している. モードは,オープンされたファイルに対しこの後許される操作,及びオープン時のどこから読み書きが始まるかを決定する. "r" は,ファイルを読み込みのためにオープンすることを意味し,ファイルの先頭から読み込みが始まる.
14行目の fopen では,書き込み先のファイルとして "dst" ,オープン時のモードとして "w" を指定している. "w" は,書き込みのためにファイルをオープンすることを意味し,ファイルが存在していなかった場合は新たに作られ,存在していた場合はファイルの長さは 0 にされる. また,書き込みはファイルの先頭から始まる.
他にモードとして指定できる文字列には,r+, w+, a, a+ (つまり rwa の文字のいずれか,又はそれに + を付けたもの)がある. r+, w+, a+ はどれも読み書きのためにファイルをオープンすることを意味するが,ファイルが存在していなかった場合の動作,また読み書きがどこから始まるか,といった点が異なる. 正確な意味は FOPEN(3) を参照(man fopen).
また,モードを指定する文字列に b を含むプログラムを目にすることがあるが,互換性のために残されているだけで,POSIXでは意味がない.
9〜12行目,15〜19行目は fopen に失敗した時の処理である. どちらも基本的に同じで,perror によりエラーメッセージを出力した後に,exit によりプログラムの実行を終了させている. exit の引数は,プロセスの終了を待っている親プロセスに渡されるが,この詳細は来週に開設する予定.
15〜19行目の処理には,"src" ファイルへのファイルポインタをクローズする fclose が入っている(17行目). エラー処理で exit してしまう場合は,全てのファイルは自動的にクローズされ,領域も開放されてしまうため,この fclose は実際は必要ない. しかし exit しない場合には,同時にオープンできるファイルには制限があり,またメモリリークが起きないようにするためにも,関連するファイルポインタを確実にクローズすることは重要である.
ファイルのコピーなどのコマンドのプログラムを作る時には,コピーするファイル名をコマンド行の引数として渡せると便利である. このようなプログラム起動時の引数は,main 関数への引数として渡される. 以下のプログラムは,コマンド行の引数を出力する.
1 #include <stdio.h>
2
3 main(int argc, char *argv[])
4 {
5 int i;
6
7 for (i = 0; i < argc; i++)
8 puts(argv[i]);
9 }
これをコンパイル実行すると以下のような結果が得られる.
% ./a.out src dst
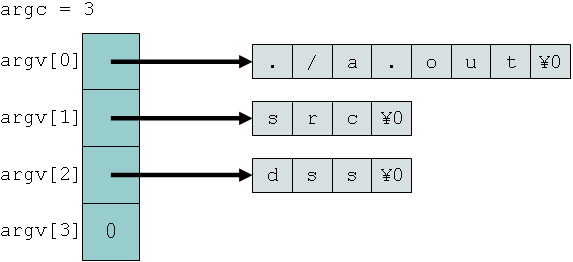
上記プログラムの3行目の main 関数の引数として argc, argv が指定されており, argc は int 型,argv は char * 型の配列(char 型へのポインタを格納する配列)である. argc は argument count,argv は argument vector の略である. main 関数の引数の名前は argc, argv である必要性はないが,慣例的に argc, argv が使われてきており,この名前で使うことがプログラムのわかりやすさの点でも望ましい.
argc にはコマンド行の文字列の個数が入る(コマンド名+引数). 上記の実行例では,argc の値は 3 になる.
argv は,コマンド行の文字列それぞれへのポインタを格納した配列である. 下図は,上記の実行例における argv の構造を図示したものである. argv[0] はコマンド名の文字列 "./a.out" , argv[1] は最初の引数 "src" , argv[2] は次の引数 "dst" , そして argv[3] 即ち argv[argc] にはNULLポインタ(要するに 0 )が格納される.
ライブラリ関数を用いてファイルのコピーを行うプログラムを,コピーするファイル名をコマンド行の引数として渡せるようにすると次のようなプログラムになる.
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 main(int argc, char *argv[])
5 {
6 int c;
7 FILE *src, *dst;
8
9 if (argc != 3) {
10 printf("Usage: %s from_file to_file\n", argv[0]);
11 exit(1);
12 }
13
14 src = fopen(argv[1], "r");
15 if (src == NULL) {
16 perror(argv[1]);
17 exit(1);
18 }
19
20 dst = fopen(argv[2], "w");
21 if (dst == NULL) {
22 perror(argv[2]);
23 fclose(src);
24 exit(1);
25 }
26
27 while ((c = fgetc(src)) != EOF)
28 fputc(c, dst);
29
30 fclose(src);
31 fclose(dst);
32 }
argc, argv を解釈する場合は,引数の数をチェックすることが大切である. 上記のプログラムでは 8〜11行目で,引数の数が 3 でなければ,そのプログラムの使い方を表示し,プログラムを終了するようにしている.
これをコンパイル実行すると以下のような結果が得られる.
% ./a.out
システムコールを用いてファイルアクセスを行うために,ファイルを開き,閉じるためには open, close を用いる. 読み書きのためのシステムコールは read, write を用いる. ライブラリ関数と異なり,read, write 以外には読み書きのためのシステムコールはない.
int open(const char *pathname, int flags); int open(const char *pathname, int flags, mode_t mode); int close(int fd); ssize_t read(int fd, void *buf, size_t count); ssize_t write(int fd, const void *buf, size_t count);
ファイルアクセスのためのシステムコールは上記の open, close, read, write である. ライブラリ関数もファイルアクセスを行うために,最終的にはシステムコールを使用する. 従って,fopen は open を呼び,fclose は close を呼ぶ. 入力のための getchar, fgetc, fgets, fread は read を呼び,出力のための putchar, fputc, fputs, fwrite は write を呼ぶ.
fopen は FILE 構造体へのポインタを返し,その後オープンしたファイルへのアクセスのためにはそのポインタを用いる. open はオープンに成功すると 0 以上の整数を返す. その整数は,ファイルディスクリプタ(ファイル記述子)と呼ばれる. システムコールを用いてファイルアクセスを行う場合は,open によりファイルをオープンした後は,戻り値のファイルディスクリプタを指定することにより,そのファイルに対し読み書きを read, write を用いて行うことができる. ファイルアクセスが終了したら,ファイルディスクリプタを引数に close を呼ぶことで,そのファイルをクローズできる.
あるプロセスが一時にオープンできるファイルの数(ファイルディスクリプタの最大値)は制限されている. 昔の UNIX では非常に少なかったが,現在はかなり多くのファイルを一時にオープンすることができる. Mac OS X では,通常のプロセスは 256 に設定されているが,unlimit により最大 10240 まで使用可能にできる(/usr/include/sys/syslimits.h の OPEN_MAX).
ライブラリ関数による入出力も結局はシステムコールを呼び出すことで実現されている. ということは,標準入出力(stdin, stdout, stderr)もシステムコールを通して入出力が処理されている. システムコールを通した入出力は,ファイルディスクリプタにより入出力先が指定されるため,標準入出力がなければおかしいことになる.
標準入出力のためのファイルディスクリプタとして 0, 1, 2 が割り当てられている. 0 が標準入力,1 が標準出力,2 が標準エラー出力に対応する. これら3つのファイルディスクリプタは,プログラムが実行される時に明示的にオープンしなくても,使える状態になっている.
ライブラリ関数を用いてファイルのコピーを行うプログラムを,システムコールを用いるように書き換えると以下のプログラムのようになる.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <fcntl.h>
4
5 main()
6 {
7 char c;
8 int src, dst;
9 int count;
10
11 src = open("src", O_RDONLY);
12 if (src < 0) {
13 perror("src");
14 exit(1);
15 }
16
17 dst = open("dst", O_WRONLY | O_CREAT | O_TRUNC, 0666);
18 if (dst < 0) {
19 perror("dst");
20 close(src);
21 exit(1);
22 }
23
24 while ((count = read(src, &c, 1)) > 0) {
25 if (write(dst, &c, count) < 0) {
26 perror("write");
27 exit(1);
28 }
29 }
30
31 if (count < 0) {
32 perror("read");
33 exit(1);
34 }
35
36 close(src);
37 close(dst);
38 }
プログラムの流れは,ライブラリ関数を用いた場合と同じである. open への引数は,オープンしたいファイル名と,ファイルをオープンするモードである. O_RDONLY は読み込みのみ,O_WRONLY は書き込みのみである. 読み書きの場合は O_RDWR を指定する. O_RDONLY, O_WRONLY, O_RDWR と一緒に設定できるモードがいくつかある. O_CREAT がセットされていると,ファイルが存在しなかった場合は作成する. O_TRUNC がセットされていると,ファイルが既に存在した場合はファイルの長さは 0 にされる. モードに O_CREAT が含まれる場合は,ファイルが作られた場合に設定するパーミッションが3番目の引数になる. 実際に設定されるパーミッションは,umask のマスクがかかった値になる.
read は読み込める最大バイト数,write は書き込める最大バイト数を指定するが,それぞれ指定されただけの最大バイト数を読み込み又は書き込みできるとは限らない. 実際に読み書きされたバイト数が read, write の戻り値として返される.
read, write で指定する読み書きの最大バイト数は,大きいほうが read, write システムコールの呼び出しとコピーの回数が少なくてすむので,より効率的である. つまり上記のプログラムのように 1 とするのは,非常に効率が悪い. 通常 1024, 4096, 8192 などの値が用いられるが,最も効率の良い値は入出力先のデバイス,デバイスを制御するコントローラ,メモリの量などに依存する.
同一のファイルに対するアクセスをライブラリとシステムコールで混ぜて行うことは,プログラミング上は可能ではあるが,結果がおかしくなる可能性があるので,避けるべきである. ライブラリ関数での入出力は,1文字単位の入出力も効率よく行えるように,入出力データを一時的に蓄えるバッファリングをすることで,システムコールの回数を減らしている. 混ぜて使うと,バッファリングされたデータとの整合性が取れなくなってしまう.
どうしても,どちらかからどちらかへ変換したい時には,以下の関数を使用することができる. fileno, fdopen は,十分なテストをするなど何をしているのか理解するよう注意して使用すべきで,安易に使用すべきではない.
fflush は,上記の目的とは関係なく,バッファリングされたデータをフラッシュしたい時にも使用できる.
int fileno(FILE *stream); /* FILE構造体のファイルディスクリプタを返す */ FILE *fdopen(int fildes, char *mode); /* ファイルディスクリプタからFILE構造体を作る */ int fflush(FILE *stream); /* バッファリングされたデータをフラッシュ */
全てをメモリ上に読み込むことが難しい大きなデータを扱う場合,全データはファイルに格納し,必要なデータのみを読み書きすることになる. その場合,データをファイルの先頭から順番に読み込んでいくシーケンシャルアクセスではなく,途中を読み飛ばす(読み書きする場所を移動する)ランダムアクセスができると効率が良い.
ランダムアクセスをするためには,システムコールの read, write を用いている場合には lseek,ライブラリ関数の fread, fwrite を用いている場合には fseek を用いる. これらは,ファイルを読み書きする位置(先頭からのバイト数)を移動する. この位置のことを,オフセット,シークポインタ,ファイルポインタなどと呼ぶ(ファイルポインタと呼ぶ場合は FILE* と紛らわしいので注意).
off_t lseek(int fildes, off_t offset, int whence); int fseek(FILE *stream, long offset, int whence);
lseek, fseek 共に指定するパラメータは同じで,第3引数の whence で指定される位置に第2引数の offset バイト数を加えることによって得られた位置に移動する. つまり,offset に負の値を指定すると,whence で指定された位置から前に移動する. whence には以下のマクロのどれかを指定する.
| SEEK_SET | ファイルの先頭から offset バイト目に移動. |
| SEEK_CUR | 現在の位置から offset バイト目に移動. |
| SEEK_END | ファイルの末尾から offset バイト目に移動. |
SEEK_END によりファイル末尾から先頭方向に向かって offset バイト目に移動したい場合(通常そうであると思われるが)は,offset には負の値を指定しなければいけないことに注意.
fread, fwriteはライブラリで実装されており,バイト単位での入出力も効率良く行えるように,バッファリングしている. また,指定したオブジェクト(レコード)単位での読み書きを保障しているため,システムコールの read, write と比較して,使いやすい. (システムコールの read, write は,実際に読めた又は書けたバイト数を戻り値として返し,引数に指定した読みたい又は書きたいバイト数の読み書きの保障はしていない.)
バッファリングをしてくれる fread, fwrite を用いる際には,自分でバッファを用意する必要は基本的にはない. しかし,ある程度の大きさのデータを読み込むため,自分で動的に領域を確保する必要がある場合はある. そのような場合を想定し,mallocでバッファを確保してのファイルコピーの例を示す.
28行目でmallocでバッファを確保している. 確保する領域のサイズを指定しているBUFSIZは stdio.h で定義されている標準的なバッファサイズを表すマクロである. 36行目にある feof は,freadの戻り値からはEOFとエラーの区別ができないため,EOFかどうかを確認するために使用している. 38, 46行目にある ferror は,同様の理由で,エラー処理を行うため,エラーを区別するために使用している.
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 main(int argc, char *argv[])
5 {
6 FILE *src, *dst;
7 void *buf;
8 int rcount, wcount;
9
10 if (argc != 3) {
11 printf("Usage: %s from_file to_file\n", argv[0]);
12 exit(1);
13 }
14
15 src = fopen(argv[1], "r");
16 if (src == NULL) {
17 perror(argv[1]);
18 exit(1);
19 }
20
21 dst = fopen(argv[2], "w");
22 if (dst == NULL) {
23 perror(argv[2]);
24 fclose(src);
25 exit(1);
26 }
27
28 buf = malloc(BUFSIZ);
29 if (buf == NULL) {
30 perror("malloc");
31 fclose(src);
32 fclose(dst);
33 exit(1);
34 }
35
36 while (!feof(src)) {
37 rcount = fread(buf, 1, BUFSIZ, src);
38 if (ferror(src)) {
39 perror("fread");
40 fclose(src);
41 fclose(dst);
42 exit(1);
43 }
44
45 wcount = fwrite(buf, 1, rcount, dst);
46 if (ferror(dst)) {
47 perror("fwrite");
48 fprintf(stderr, "tried to write %d bytes, "
49 "but only %d bytes were written.\n", rcount, wcount);
50 fclose(src);
51 fclose(dst);
52 exit(1);
53 }
54 }
55
56 fclose(src);
57 fclose(dst);
58 }
まとめて扱うと便利なデータは,Cプログラムでは構造体を用いて表現する. 例えば住所録を作る場合,名前,住所,電話番号,メイルアドレスなどを構造体としてまとめて扱うと,ソートや検索など様々な処理がしやすくなる.
そのような構造体のデータをファイルに保存,または読み出すために,まず知らなくてはならないことは,構造体の大きさである. 住所録のそれぞれのエントリのために,以下のような構造体を定義したとする.
1 struct entry {
2 char name_family[32];
3 char name_first[32];
4 char addr[128];
5 int zip1;
6 int zip2;
7 char mail[128];
8 };
この構造体の大きさを知るためには sizeof 演算子を用いる. struct entry の定義は addr.h に書かれているとすると,以下のプログラムはそのバイト数を表示する.
1 #include <stdio.h>
2 #include "addr.h"
3
4 main()
5 {
6 printf("sizeof(struct addr) = %d\n", sizeof(struct entry));
7 }
コンパイル実行すると,以下のようになる.
% ./a.out
struct entry は,名前に32バイト配列が2つ,住所とメイルに128バイトの配列が2つ,郵便番号に4バイトの int が2つ使用しているため,合計328となり,上記の実行結果と一致する.
構造体の大きさは,必ずしもメンバの大きさの単純な和にはなるとは限らないことに注意 →データファイルのポータビリティ
/var/run/utmp というファイルには現在ログインしているユーザが記録されている. 以下のプログラムは fread を利用し1エントリごとデータを読み込み,ログインユーザを表示するプログラムである.
struct utmp の定義は /usr/include/utmp.h から読み込まれる. 10行目の _PATH_UTMP は /var/run/utmp を表す. マクロになっているのはUNIXのバージョンによりパスが異なっていることがあるためであり,マクロにすることによりプログラムの移植性を高めることができる. (しかしながらUNIXの系統によっては異なるマクロが使われている. Linuxでは _PATH_UTMP ではなく UTMP_FILE となっている.)
18行目で読み込んだエントリを19〜20行目で出力している. printf の出力フォーマットで %8.8s のピリオド(.)の前の8は8桁のフィールド幅を確保することを意味し,またピリオドの後ろの8は出力する最大文字数を表す. 即ち,%8.8s は常に8文字分のフィールドにはみ出さないように出力されることを意味する.
注:下記のプログラムは Linux では動作するが,Mac OS X では utmp ファイルがなくなり実行できない.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <time.h>
4 #include <utmp.h>
5
6 main()
7 {
8 FILE *fp ;
9 struct utmp u;
10
11 fp = fopen(_PATH_UTMP, "r");
12
13 if (fp == NULL) {
14 perror(_PATH_UTMP);
15 exit(-1);
16 }
17
18 while (fread(&u, sizeof(u), 1, fp) == 1) {
19 printf("%8.8s|%16.16s|%8.8s|%s", u.ut_name,
20 u.ut_host, u.ut_line, ctime(&u.ut_time));
21 }
22
23 fclose(fp);
24 }
上記プログラムをコンパイル実行すると以下のようになる(結果は各コンピュータごとに異なる).
% ./a.out
上記のプログラムは Mac OS X では utmp ファイルがなくなり実行できない. 代わりに,utmpx ファイルのエントリを順次読み込む getutxent を用いる. getutxent は,固定の領域に utmpx ファイルのエントリを読み込むため,次の呼び出しで内容は上書きされてしまうことに注意する. 以下は getutxent を用いたプログラムである.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <time.h>
4 #include <utmpx.h>
5
6 main()
7 {
8 struct utmpx *up;
9
10 while ((up = getutxent()) != NULL) {
11 printf("%8.8s|%16.16s|%8.8s|%s", up->ut_user,
12 up->ut_host, up->ut_line, ctime(&up->ut_tv.tv_sec));
13 }
14 }
構造体のデータを書き込み作成したデータを様々なコンピュータで共有しようとする時に注意しなければいけないのは,データがどのようにファイルに書かれているのかという点である. 即ち,数値データがどのようにメモリ上で表現されているのかについて知る必要がある. 例えば,以下のような点について気をつける必要がある.
ある意味,最もポータビリティが高いのは1バイトごとにアクセスできるテキストファイルである. 例えば,様々なデータを扱えるように設計されたXMLはテキスト形式である.
utmpファイルの各エントリの内容を保持するリストを作ることを考える. 読み込むレコードが固定長ならば,ファイルのサイズから必要な領域のサイズを計算することもできるが,ここではエントリ読み込む度に必要な領域を動的に確保してみる.
7~10行目でリストを作る構造体を定義している. メンバnextが次の要素へのポインタであり,メンバuはutmp構造体である. つまり,構造体の中に構造体を埋め込んでいる. 24~43行目のforループで,領域を確保し,そこへエントリを読み込み,リストをアップデートしている. 作成したリストは48~54行目で出力している.
注:下記のプログラムは Linux では動作するが,Mac OS X では utmp ファイルがなくなり実行できない.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <strings.h>
4 #include <time.h>
5 #include <utmp.h>
6
7 struct utmplist {
8 struct utmplist *next;
9 struct utmp u;
10 };
11
12 main()
13 {
14 FILE *fp ;
15 struct utmplist *ulhead = NULL;
16 struct utmplist *ulprev, *ulp;
17
18 fp = fopen(_PATH_UTMP, "r");
19 if (fp == NULL) {
20 perror(_PATH_UTMP);
21 exit(-1);
22 }
23
24 for (;;) {
25 ulp = calloc(1, sizeof(struct utmplist));
26 if (ulp == NULL) {
27 perror("calloc");
28 fclose(fp);
29 exit(-1);
30 }
31
32 if (fread(&ulp->u, sizeof(ulp->u), 1, fp) != 1) {
33 free(ulp);
34 break;
35 }
36
37 if (ulhead == NULL)
38 ulhead = ulp;
39 else
40 ulprev->next = ulp;
41
42 ulprev = ulp;
43 }
44
45 fclose(fp);
46 ulp = ulhead;
47
48 while (ulp) {
49 printf("%8.8s|%16.16s|%8.8s|%s", ulp->u.ut_name,
50 ulp->u.ut_host, ulp->u.ut_line, ctime(&ulp->u.ut_time));
51 ulprev = ulp;
52 ulp = ulp->next;
53 free(ulprev);
54 }
55 }
上記の utmp ファイルを読み込むプログラムは main 関数が長くなり,やや読みにくい.
そこで、読み込み部と書き出し部を関数に分け構造化したプログラムを以下に示す.
関数単位で内容を把握することができ,わかりやすくなる.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <strings.h>
4 #include <time.h>
5 #include <utmp.h>
6
7 struct utmplist {
8 struct utmplist *next;
9 struct utmp u;
10 };
11
12 struct utmplist *
13 read_utmp(FILE *fp, struct utmplist *head)
14 {
15 struct utmplist *ulprev, *ulp;
16
17 for (;;) {
18 ulp = calloc(1, sizeof(struct utmplist));
19 if (ulp == NULL) {
20 perror("calloc");
21 fclose(fp);
22 exit(-1);
23 }
24
25 if (fread(&ulp->u, sizeof(ulp->u), 1, fp) != 1) {
26 free(ulp);
27 break;
28 }
29
30 if (head == NULL)
31 head = ulp;
32 else
33 ulprev->next = ulp;
34
35 ulprev = ulp;
36 }
37
38 return head;
39 }
40
41 void
42 write_utmp(FILE *fp, struct utmplist *head)
43 {
44 struct utmplist *ulprev;
45 struct utmplist *ulp = head;
46
47 while (ulp) {
48 fprintf(fp, "%8.8s|%16.16s|%8.8s|%s", ulp->u.ut_name,
49 ulp->u.ut_host, ulp->u.ut_line, ctime(&ulp->u.ut_time));
50 ulprev = ulp;
51 ulp = ulp->next;
52 free(ulprev);
53 }
54 }
55
56 main()
57 {
58 FILE *fp ;
59 struct utmplist *ulhead = NULL;
60
61 fp = fopen(_PATH_UTMP, "r");
62 if (fp == NULL) {
63 perror(_PATH_UTMP);
64 exit(-1);
65 }
66
67 ulhead = read_utmp(fp, ulhead);
68
69 fclose(fp);
70
71 write_utmp(stdout, ulhead);
72 }
ファイルの内容にアクセスする方法で,これまで見てきた read, write を用いる方法とは全く違った方法として,ファイルをアドレス空間にマップするメモリマッピング又はメモリマップドファイル (memory mapped file) と呼ばれる方法がある. ファイルをアドレス空間にマップすることで,ファイルの内容は配列のように扱うことができ,配列の添字やポインタを用いてアクセスできるようになる.
メモリマッピングを行うためには,mmap システムコールを使用する.
void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset); int munmap(void *addr, size_t length);
mmap はファイルディスクリプタ (fd) で指定されたファイルをアドレス空間にマップする. 引数として,ファイルのどの位置 (offset) からどれだけの長さ (length) をマップするか指定する. また,マップされた領域のメモリ保護 (prot) とタイプ (flags) も指定する.
munmap は,mmapした領域を解放する.
_PATH_WTMP をアクセスするプログラムを,メモリマッピングを用いるように変更すると以下のようになる. 変更点は以下の通りである.
注:下記のプログラムは Linux では動作するが,Mac OS X では utmp ファイルがなくなり実行できない.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <time.h>
4 #include <utmp.h>
5 #include <fcntl.h>
6 #include <sys/types.h>
7 #include <sys/stat.h>
8 #include <sys/mman.h>
9
10 main()
11 {
12 int fd, num, err;
13 struct stat fs;
14 struct utmp *u;
15
16 fd = open(_PATH_WTMP, O_RDONLY);
17 if (fd < 0) {
18 perror(_PATH_WTMP);
19 exit(-1);
20 }
21
22 if (fstat(fd, &fs) < 0) {
23 perror("fstat");
24 exit(-1);
25 }
26
27 u = mmap(NULL, fs.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
28 if (u == MAP_FAILED) {
29 perror("mmap");
30 exit(-1);
31 }
32
33 num = fs.st_size / sizeof(struct utmp);
34
35 while (num--) {
36 printf("%8.8s|%16.16s|%8.8s|%s", u->ut_name,
37 u->ut_host, u->ut_line, ctime(&u->ut_time));
38 u++;
39 }
40
41 err = munmap(u, fs.st_size);
42 if (err) {
43 perror("munmap");
44 exit(-1);
45 }
46 close(fd);
47 }
上記プログラムをコンパイル実行すると,fread で読み込むプログラムが表示する情報と同じ情報が表示される.
以下は,自分でバッファを確保してのファイルコピーの28~34行目を #if 0 ~ #endif で囲み,コンパイル時に無視(正確には cpp プリプロセッサにより削除)されるようにすることで,mallocによる動的メモリ確保が行われないようにしたプログラムである. 7行目で void * 型の変数 buf が宣言されているが,初期化されず,その値は不定のまま,39, 47行目で読み書きのバッファに指定されている. buf は有効なメモリ領域を指していないため,実行するとエラーになることが多い. 例え実行できてしまったとしても,どこかの領域を破壊している可能性が高い.
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 main(int argc, char *argv[])
5 {
6 FILE *src, *dst;
7 void *buf;
8 int rcount, wcount;
9
10 if (argc != 3) {
11 printf("Usage: %s from_file to_file\n", argv[0]);
12 exit(1);
13 }
14
15 src = fopen(argv[1], "r");
16 if (src == NULL) {
17 perror(argv[1]);
18 exit(1);
19 }
20
21 dst = fopen(argv[2], "w");
22 if (dst == NULL) {
23 perror(argv[2]);
24 fclose(src);
25 exit(1);
26 }
27
28 #if 0
29 buf = malloc(BUFSIZ);
30 if (buf == NULL) {
31 perror("malloc");
32 fclose(src);
33 fclose(dst);
34 exit(1);
35 }
36 #endif
37
38 while (!feof(src)) {
39 rcount = fread(buf, 1, BUFSIZ, src);
40 if (ferror(src)) {
41 perror("fwrite");
42 fclose(src);
43 fclose(dst);
44 exit(1);
45 }
46
47 wcount = fwrite(buf, 1, rcount, dst);
48 if (ferror(dst)) {
49 perror("fwrite");
50 fprintf(stderr, "tried to write %d bytes, "
51 "but only %d bytes were written.\n", rcount, wcount);
52 fclose(src);
53 fclose(dst);
54 exit(1);
55 }
56 }
57
58 fclose(src);
59 fclose(dst);
60 }
しかしながら,このプログラムはコンパイルできてしまう. しかも,単純に cc コマンドをオプション無しで使用してコンパイルすると,何の警告も出力されないことが多い.
以下のように cc に -O -Wall という2つのオプションを付けてコンパイルすると,buf が初期化されずに使用されているという警告が出力される. (-O だけ,または -Wall だけでは警告は出力されない.両方のオプションを指定する必要がある.) その他,いろいろな警告を出力してくれるため,必要に応じて,このようなオプションを指定すると良い.
% cc -Wall -O bad-filecopy.c
変数には,基本的には,グローバル変数とローカル変数があるが,変数名の有効範囲(スコープ)だけでなく,その領域が有効な期間についても理解し,プログラミング時には意識しなければならない. ヒープ領域も加え,それぞれの有効期間について以下にまとめる.
グローバル変数が使用する領域は,プログラム実行開始から終了まで有効である. 実行中確保された状態が変化することがないため,静的な領域確保という言い方もする. 初期値を持つもの,持たない(初期値が0)ものに区別され,それぞれデータセグメント(セクション),BSSセグメントに置かれる. プログラム実行開始時に,必要な大きさの領域が確保され,データセグメントはプログラムファイルから読み込まれ,BSSセグメントは0に初期化される. この領域はプログラムの実行が終了するまで開放されることがなく,また解放することも出来ない. 逆に言うと,実行開始時に必要なメモリが確保できない場合は,プログラムの実行を開始できない. そして,使用されているか否かに関わらず,メモリを使用し続けてしまう.
ローカル変数が使用する領域は,宣言された関数が呼び出されてから呼び出し元に戻るまで有効である.
その関数が別の関数を呼び出した場合も(末尾呼び出しの場合を除き)その関数が return するまで,ローカル変数は有効である.
つまり,関数 func1 で宣言されたローカル変数 var1 は,func1 から呼び出される func2 を実行中も,領域としては有効なままである.
従って,func2 に引数として var1 へのポインタ(&var1)を渡しても,var1 の領域が有効であるため,func2 でその領域を使用することができる.
逆に,func1 の戻り値として &var を返すことは,func1 の return 後にその領域は無効になるため,できない.
ローカル変数が使用する領域は,スタック上に確保される.
スタックは関数呼び出しの際に伸び,戻る際に縮む.
従って,その領域は再利用を繰り返していることになる.
そのスタックのための領域の大きさは,システムによって異なる.
必要なだけ伸びていくシステムも多いが,サイズが固定されているシステムもある.
そのため,大きなデータをスタック上に確保するようなプログラムは,システムにより動作したりしなかったり,ということが起こる可能性がある.
ヒープ領域はプログラム実行開始後,必要にな時に確保され不要になったら解放される領域であり,確保から解放まで有効である. 実行中に確保,解放され,確保された状態が変化するため,動的な領域確保という言い方をする. 確保,解放は,明示的に行われる. 実行時に確保されるため,確保された領域を指し示す方法はポインタしかない.
ポインタを用いる場合,その指し示す先がどの領域であるか,常に意識し,有効な領域を正しく使用しなければならない.
バッファオーバーフローはプログラムの実行(プロセス)を乗っ取るため,悪意を持った攻撃者によって引き起こされる. バッファオーバーフローを起こすことにより,攻撃者は任意のプログラムを送り込み,それを実行することができてしまい,プロセスは乗っ取られてしまう.
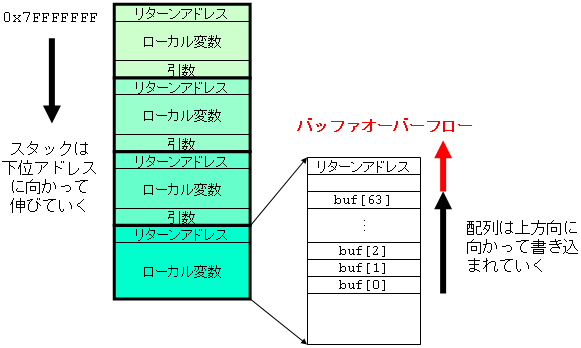
バッファオーバーフローがどうして起こるのか理解するためには,プロセスが実行時に用いられるスタックの構造について理解する必要がある.
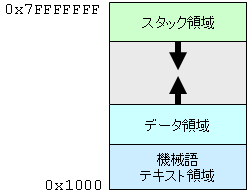
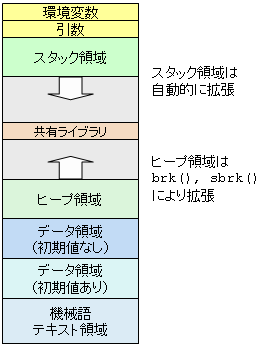
下図は,実行中のプロセスのメモリ空間においてどのようにデータが配置されているかを図示したものである. 通常,最も下位アドレスに機械語命令が入ったテキスト領域が置かれる. その上にデータ領域が置かれる. データ領域とは別に,関数呼び出し時の戻りアドレス(リターンアドレス)や関数のローカル変数が格納されるスタック領域がある. データ領域はデータ割り当てが起こるたびに上位アドレスに向かって伸びていく. スタック領域は逆に,関数呼び出しが起こるたびに下位アドレスに向かって伸びていく.
スタック領域をより詳細に図示すると下図のようになる. 関数呼び出しが起こると,リターンアドレスがスタックにプッシュされ,呼び出された関数で使用するローカル変数のための領域が確保される. リターンアドレスとローカル変数のための領域を合わせてスタックフレームと呼ぶ.
スタックフレーム中のローカル変数に配列が含まれていると,配列の添字が小さいほうが下位アドレスにあり,大きいほうが上位アドレスにくる. 上の図で buf がポインタとして例えば gets に渡されると,buf[0] から上位アドレスに向かって書き込まれていく. 64文字以上の文字が書き込まれると,buf[63] を超えて書き込まれ,buf として割り当てられた領域を超えて書き込まれてしまうことになる. さらに書き込まれると,リターンアドレスも書き換えられてしまう. スタック領域にうまくプログラムを書き込み,リターンアドレスをそのプログラムの開始アドレスに設定してあげると,関数が戻る時に書き込んだプログラムが実行されてしまう.
このような攻撃方法をスタックスマッシング (stack smashing) と呼ぶ.
以下はスタックを破壊してしまうプログラムの例である.
1 #include <stdio.h>
2 #include <string.h>
3
4 char *longstr = "01234567890abcdefghijklmnopqrstuvwxyz"
5 "01234567890abcdefghijklmnopqrstuvwxyz"
6 "01234567890abcdefghijklmnopqrstuvwxyz"
7 "01234567890abcdefghijklmnopqrstuvwxyz"
8 "01234567890abcdefghijklmnopqrstuvwxyz"
9 "01234567890abcdefghijklmnopqrstuvwxyz";
10
11 void
12 with_check(char *src)
13 {
14 char buf[20];
15 int i;
16
17 i = strlcpy(buf, src, sizeof(buf));
18
19 if (i > sizeof(buf) - 1)
20 printf("with_check: buf is too short to copy src(%s).\n",
21 src);
22
23 printf("with_check: buf(%s)\n", buf);
24 }
25
26 void
27 without_check(char *src)
28 {
29 char buf[20];
30 strcpy(buf, src);
31 printf("without_check: buf(%s)\n", buf);
32 }
33
34 main()
35 {
36 with_check(longstr);
37 without_check(longstr);
38 }
これをコンパイル実行すると,without_check関数を実行中にスタックが破壊され,without_check関数を呼び出したmain関数に戻る際におかしなアドレスに戻ろうとするため,以下のように異常終了してしまう.
% ./a.out
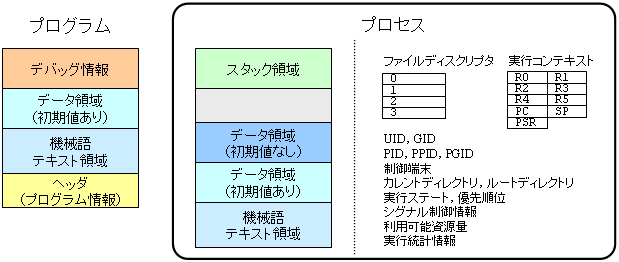
プログラムは,CPUが実行できる機械語命令とそれにより処理されるデータの集合(実行形式,ロードモジュール)がファイルに格納されたものである. 他に,ヘッダと呼ばれる部分には機械語命令やデータなどの各領域の情報が含まれ,また共有ライブラリを用いるように動的リンクされた実行形式の場合は実行に必要な共有ライブラリの情報,ソースコードレベルのデバッグ情報付きでコンパイル(cc -g)された実行形式の場合はデバッグ情報なども含まれる.
一方,プログラムを実行中のものがプロセスである. プロセスには,プログラムに含まれる実行に必要な情報に加えて,プログラムには含まれない実行中の情報が入っている. 初期値が 0 (初期値なし)のデータ領域はプログラムに含める必要性はなく,そのデータ領域がプロセス中のどこにどれだけの大きさ必要かという情報だけが含まれていればよい. しかし,プログラムの実行にはそのデータ領域が必要であるため,プロセスではそのデータ領域が実際に確保されている必要がある. 逆に,ヘッダ情報やデバッグ情報は必要があればプログラムファイルから読み込めばよく,プロセスでの実行には必要ない. 実行が進めばデータは書き換えられたり,追加されたりする(機械語命令は通常変わらない). プログラムには含まれていない,実行の履歴(関数呼び出し,ローカル変数)を格納するためのデータ領域(スタック)も必要である.
プロセスの重要な機能として以下の2つがある.
UNIXにおけるプロセスは,プロセッサ時間,メモリ,ファイル,キーボードやディスプレイ,プリンタなどのデバイスといった,処理を行うにあたって必要となる計算資源の割り当て単位である. ユーザがプログラムを起動すると,それはプロセスにより実行される. OSカーネルにより,プロセスに対しプロセッサ時間,メモリが割り当てられ実行が始まる. プロセスは,プログラムに記述された通りにファイルをオープン,アクセスし,キーボードやディスプレイなどのデバイスを使用する. ファイルをオープンした時に得るファイルディスクリプタは各プロセス固有のものになる. ファイルのアクセス権はユーザに対し与えられるが,計算資源はプロセスに対し与えられる.
基本的には,OSカーネルは,プロセッサ時間やメモリに関しては,それぞれのプロセスに平等になるように割り当てる. ファイルやデバイスに関しては先着順である.
プロセスは,割り当てられた資源が保護される単位でもある. あるプロセスは他のプロセスに割り当てられた資源に対し許可なくアクセスすることはできない. 例え同じユーザにより作成されたプロセス間であってもである. 保護の機能により,例えばある暴走したプロセスが他のプロセスの実行内容を破壊するようなことは起こらない.
プロセスのメモリマップを詳しく見ると以下のようになる.
それぞれの領域の用途は以下の通りである:
| テキスト領域 | プログラムの機械語命令が置かれる.この領域は読み出し専用になっており,同じプログラムから起動されるプロセスの間で共有可能になっている. |
| データ領域(初期値あり) | プログラム中に指定された 0 以外の初期値を持つ大域 (global) 変数,静的局所 (static local) 変数が置かれる. |
| データ領域(初期値なし) | 通称 BSS (Block Started by Symbol) セグメント.初期値を持たない,又は初期値が 0 の大域変数,静的局所変数が置かれる.プロセス作成時に確保され,0 に初期化される. 変数の名前(シンボル)だけなのが名前の由来. |
| ヒープ領域 | malloc()などにより,プロセス実行時に確保されるデータ領域. |
| 共有ライブラリ | 共有ライブラリのため領域はヒープとスタックの間にとられる.テキスト領域と同じく読み出し専用で,他のプログラムと共有される. |
| スタック領域 | C言語の自動変数(staticでないローカル変数)や,引数,関数呼び出し時の戻り番地などが置かれる. |
| 引数,環境変数 | コマンドに渡される引数,環境変数は,スタック領域の最上位部分に格納されている. |
上記のメモリマップは,以下の簡単なプログラムで確かめることができる. 環境変数が格納されている文字列へのポインタは environ という変数に格納されている. 初期値が設定されない data0 はBSSセクションに配置され,初期値を持つ data1 はデータセクションに配置される.
1 #include <stdio.h>
2
3 extern char **environ;
4
5 int data0;
6 int data1 = 10;
7
8 main(int argc, char *argv[])
9 {
10 char c;
11
12 printf("environ:\t%0.8p\n", environ);
13 printf("argv:\t\t%0.8p\n", argv);
14 printf("stack:\t\t%0.8p\n", &c);
15
16 printf("bss:\t\t%0.8p\n", &data0);
17 printf("data:\t\t%0.8p\n", &data1);
18 }
このプログラムをコンパイル実行してみると,以下のような結果が得られ,環境変数の文字列が最上位アドレスにあり,次にコマンド引数の文字列,そしてスタックの順であることがわかる. また,BSSセクションがデータセクションよりも上位アドレスに来ていることもわかる.
% ./a.out
| PID(プロセスID) | それぞれのプロセスにつけられる,プロセスを識別するための番号.Linuxでは 0〜32767 の範囲の整数. |
| PPID(親プロセスID) | そのプロセスを作成したプロセス(親プロセス)のプロセスID. |
| PGID(プロセスグループID) | 所属するプロセスグループのID.プロセスグループは,まとめてシグナルを送る場合などに使用される. |
| UID(ユーザID) | プロセスを実行したユーザのID.これとは別にアクセス権限を表す実効ユーザIDもある. |
| GID(グループID) | プロセスを実行したグループのID.これとは別にアクセス権限を表す実効グループIDもある. |
| ファイルディスクリプタ | オープンしたファイルの表. |
| umask | ファイル作成時のモードを決める時に,マスク値として使用される値. |
| 制御端末 | シグナルを受け取る端末. |
| カレントディレクトリ | 現在のディレクトリ.相対パス名を使う場合の出発点となる.current working directoryとも言う. |
| ルートディレクトリ | ルートディレクトリはプロセスごとに決めることができる.通常,アクセスできるファイルを制限するために使用する. |
| 実行ステート | 実行中か,停止中か,ゾンビ状態か,などのプロセスの実行状態. |
| 優先順位 | プロセスの実行優先順位. |
| シグナル制御情報 | シグナルに対応してどの処理が行われるかの情報. |
| 利用可能資源量 | プロセスの使える資源の上限. |
| 実行統計情報 | これまでの資源利用量の統計情報. |
メモリマップを確かめるプログラムに既に出てきたが,プロセスには環境変数は文字列で渡され,その文字列の場所は外部変数 environ により指し示される. 環境変数を構成する文字列は,構造的には argv と同じであり,environ は文字列の配列へのポインタ(従って型は char ** )である.
環境変数を(便利に)操作するために以下のライブラリ関数が用意されている.
char *getenv(const char *name); int putenv(char *string); int setenv(const char *name, const char *value, int overwrite); void unsetenv(const char *name);
プロセスに対して何らかの操作を行うプログラムにはいろいろある. 以下は一部のよく使用するコマンドである.
| シェル(sh, ksh, bash, zsh, csh, tcsh) | コマンドの実行(プロセス作成,プログラム実行),リダイレクション,パイプ,その他... |
| ps, pstree, top | プロセスの観察 |
| kill | プロセスの(強制)終了 |
| nice | プロセスの実行優先順位の制御 |
| limit | プロセスの利用可能資源の制御 |
| gdb | デバッグツール |
これらのコマンドは,他のプログラムと何ら変わることが無く,様々なシステムコールを呼び出すことで,その機能を実現している.
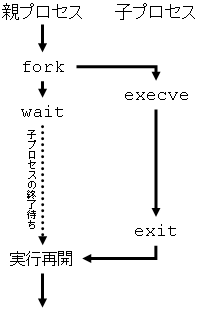
ユーザのプログラムはプロセスにより実行される. 通常,ユーザがシェルのコマンドプロンプトのところにコマンド名を打ち込むと,そのコマンドが実行される. この処理をもう少し詳しく見てみると,
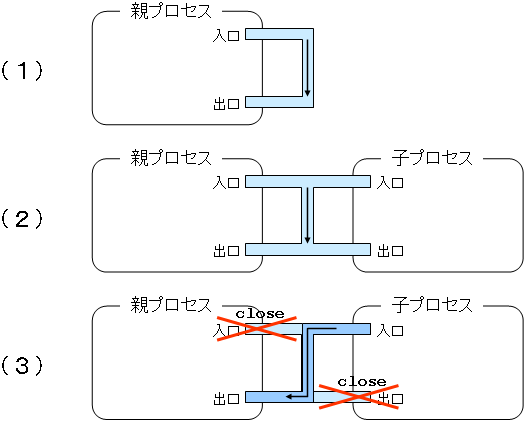
pid_t fork(void); int execve (const char *filename, char *const argv[], char *const envp[]); pid_t wait(int *status) void exit(int status);
fork システムコールは,fork システムコールを呼んだプロセスの複製を作成する. fork システムコールを呼んだプロセスが親プロセスとなり,複製され新たに作られたプロセスが子プロセスになる. execve システムコールは,execve システムコールを呼んだプロセスに指定されたプログラムをロード,実行する. wait システムコールは,子プロセスの終了を待つ. exit システムコールは,exit システムコールを呼んだプロセスを終了させる.
fork, execve, wait, exit によるプロセスの作成,プログラムの実行,プロセスの終了を図示すると以下のようになる.
UNIXでは,プロセスの作成はfork,プログラムの実行はexecveでしかできない. (Linuxにはcloneというシステムコールがあるが,これはスレッドをサポートするために無理矢理入れたものであり,ちょっと邪道である.)
forkによるプロセスの作成とexecveによるプログラムの実行というのは,一見不可解な組み合わせかもしれない. 1つのシステムコールでプロセスの作成しプログラムを実行してしまえば良いではないかと思うかもしれない. しかし,次のリダイレクションやパイプを見てみると,forkとexecveの組み合わせになっているなぞが(少しは)解けるかもしれない.
以下は,簡単のために exec をせず,fork, wait, exitだけを使ったプログラム例である.
forkは自分をコピーして子プロセスを作る. 現在実行中の場所もコピーする. 従って,子プロセスは fork から戻るところからプロセスの実行が始まる(19行目). fork を呼び出した親プロセスも fork から戻る(同じく19行目). どちらが親でどちらが子かは,fork の戻り値から判別することができる(24行目). fork は親プロセスには生成した子プロセスのプロセスIDを戻り値として返す. 子プロセスには 0 を返す. fork が失敗した時には負の値を返す.
親プロセスは fork の後 wait を呼び出し,子プロセスが終了するまで実行を一時停止する(27行目).
子プロセスは getpid で取得したプロセスIDと共にメッセージを表示した後,exit を呼んでプロセスを終了する(12行目). exit の引数として 2 を与えており,この値は wait で待っている親プロセスに渡される.
子プロセスが終了すると,wait で待っている親プロセスの実行は再開され,wait の呼び出しから戻る. 戻るときに status の値がセットされる(27行目). この status に,子プロセスが exit を呼び出した時の引数の値がセットされている. その値を取り出すために WEXITSTATUS というマクロが使われる(32行目).
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <sys/types.h>
4 #include <sys/wait.h>
5
6 void
7 do_child()
8 {
9 printf("This is child(pid=%d).\n", getpid());
10
11 exit(2);
12 }
13
14 main()
15 {
16 int child, status;
17
18 if ((child = fork()) < 0) {
19 perror("fork");
20 exit(1);
21 }
22
23 if (child == 0)
24 do_child();
25 else {
26 if (wait(&status) < 0) {
27 perror("wait");
28 exit(1);
29 }
30 printf("The child (pid=%d) existed with status(%d).\n",
31 child, WEXITSTATUS(status));
32 }
33 }
以下は,このプログラムをコンパイル,実行してみた結果である. 親プロセスが受け取る fork の戻り値と,子プロセスが getpid で取得するプロセスIDが同じであること,また子プロセスでの exit の引数が,親プロセスの wait に渡されていることがわかる.
% ./a.out
以下は execve を使用した簡単なプログラム例である. このプログラムは /bin/ls を引数なしで実行する. このプログラムを実行すると,そのプロセスに /bin/ls のプログラムが上書きされるようにロードされ /bin/ls プログラムの main 関数から実行が始まる. 即ち,/bin/ls を実行するプロセスになってしまう.
execve には,引数,環境変数はそれぞれプロセスが必要とする形式(argv形式)で渡す必要がある. argv は,char* 型の配列を宣言し(7行目),要素に値をセットしている(9, 10行目). 環境変数は,現在の環境変数の値をそのまま渡している.
execve は,シェルのように実行するプログラムを,パスをサーチしてみつけるようなことはしてくれない. 従って,実行するプログラムは絶対パスで指定する必要がある(9行目).
1 #include <stdio.h>
2
3 extern char **environ;
4
5 main()
6 {
7 char *argv[2];
8
9 argv[0] = "/bin/ls";
10 argv[1] = NULL;
11
12 execve(argv[0], argv, environ);
13 }
実際に execve が実行するプログラムは,execve の第1引数で指定されたプログラムである. そのプロセスに,execve の第2引数に指定された argv が渡される. 従って,以下のように書いても,/bin/ls は実行できる.
1 #include <stdio.h>
2
3 extern char **environ;
4
5 main()
6 {
7 char *argv[2];
8
9 argv[0] = "ls";
10 argv[1] = NULL;
11
12 execve("/bin/ls", argv, environ);
13 }
execve で実行するプログラムに引数を与えたい場合は,argv[1] 以降に指定すれば良い. 以下は /bin/ls / を実行するプログラム例である.
1 #include <stdio.h>
2
3 extern char **environ;
4
5 main()
6 {
7 char *argv[3];
8
9 argv[0] = "/bin/ls";
10 argv[1] = "/";
11 argv[2] = NULL;
12
13 execve(argv[0], argv, environ);
14 }
実行してみると,ルートディレクトリの内容が表示され,正しく引数が渡されていることがわかる.
% ./a.out
上記の fork のプログラムと execve のプログラムを組み合わせると,以下のようになる.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <sys/types.h>
4 #include <sys/wait.h>
5
6 extern char **environ;
7
8 void
9 do_child()
10 {
11 char *argv[3];
12
13 printf("This is child(pid=%d)\n", getpid());
14
15 argv[0] = "/bin/ls";
16 argv[1] = "/";
17 argv[2] = NULL;
18
19 execve(argv[0], argv, environ);
20 }
21
22 main()
23 {
24 int child, status;
25
26 if ((child = fork()) < 0) {
27 perror("fork");
28 exit(1);
29 }
30
31 if (child == 0)
32 do_child();
33 else {
34 if (wait(&status) < 0) {
35 perror("wait");
36 exit(1);
37 }
38 printf("The child (pid=%d) existed with status(%d).\n",
39 child, WEXITSTATUS(status));
40 }
41 }
実行結果としては,何ら変わりはないが,exit status は /bin/ls が設定しているため 0 になっている.
% ./a.out
実際に execve を使ったプログラムを書く場合,execve が失敗する可能性も考えなければならない. execve はプログラムの実行に失敗すると負の整数の戻り値を返す. 以下は,その処理を追加し(17〜20行目),存在しないプログラムを実行しようとしてみた例である.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <sys/types.h>
4 #include <sys/wait.h>
5
6 extern char **environ;
7
8 void
9 do_child()
10 {
11 char *argv[2];
12
13 printf("This is child(pid=%d)\n", getpid());
14
15 argv[0] = "/bin/xxxxx";
16 argv[1] = NULL;
17
18 if (execve(argv[0], argv, environ) < 0) {
19 perror("execve");
20 exit(1);
21 }
22 }
23
24 main()
25 {
26 int child, status;
27
28 if ((child = fork()) < 0) {
29 perror("fork");
30 exit(1);
31 }
32
33 if (child == 0)
34 do_child();
35 else {
36 if (wait(&status) < 0) {
37 perror("wait");
38 exit(1);
39 }
40 printf("The child (pid=%d) existed with status(%d).\n",
41 child, WEXITSTATUS(status));
42 }
43 }
上記のプログラムを実行してみると,execve は失敗し,perror の出力するエラーメッセージが表示される.
% ./a.out
exit は現在はライブラリ関数となっており,_exit がシステムコールである. 特定のプロセスの終了を待つには waitpid を使用する.
void _exit(int status); pid_t waitpid(pid_t pid, int *status, int options);
なぜ exit はライブラリ関数になっているのかは,atexit(3) を見てみるとわかる.
execve は引数や環境変数を argv 形式で渡す必要がある,またプログラムのサーチしてくれないため,もう少し簡単に使えるようにと,以下のライブラリ関数が用意されている.
int execl(const char *path, const char *arg, ...); int execlp(const char *file, const char *arg, ...); int execle(const char *path, const char *arg , ..., char * const envp[]); int execv(const char *path, char *const argv[]); int execvp(const char *file, char *const argv[]);
execl, execlp, execle は,コマンド引数の渡し方が execve とは異なり,これらのライブラリ関数の引数として,コマンド引数ののように文字列を並べて渡す.
1 #include <stdio.h>
2 #include <unistd.h>
3
4 main()
5 {
6 execl("/bin/ls", "ls", "/", NULL);
7 }
また,execlp, execvp は環境変数 PATH を使用してコマンドをサーチしてくれる.
1 #include <stdio.h>
2 #include <unistd.h>
3
4 main()
5 {
6 execlp("ls", "ls", "/", NULL);
7 }
リダイレクションは標準入出力をファイルにする機能である. 以下は,シェルから ls の結果をファイルに出力したり,wc への入力をファイルにしたりしている.
% ls *.c > a.txt
リダイレクションにより入出力をファイルに対して行うという処理は ls, wc とは無関係に行われている. プロセスの標準入出力は,ファイルディスクリプタの 0, 1, 2 に割り当てられている. これらのファイルディスクリプタの先が何であるかは,プロセスは関知しない. プロセスは 0 は標準入力,1 は標準出力,2 は標準エラー出力であるとして処理を行う.
execve はプログラムを実行するためにプロセスのメモリ空間を上書きしそのプログラムの main 関数から実行を始めるが,ファイルディスクリプタを含めその他の属性は変更しない. そこでファイルディスクリプタ 0 の先をファイルにしてしまってから execve を呼ぶと,execve によって起動されるプログラムが標準入力はそのファイルになってしまう. 従って,標準入力からの読み込みを行うと,そのファイルの内容が読み込まれることになる. また,ファイルディスクリプタ 1 の先をファイルにしてしまってから execve を呼ぶと,execve によって起動されるプログラムが標準出力への書き込みは,そのファイルへの書き込みとなる.
ファイルの入出力のためのファイルディスクリプタの値として 0, 1, 2 を使用するには,ファイルディスクリプタの付け替えをしてくれるシステムコール dup, dup2 を呼ぶ. どちらも指定されたファイルディスクリプタの複製を作成する. 呼出し後は,古いファイルディスクリプタも dup, dup2 によって作成された新しいファイルディスクリプタも,同じものとして使用できる状態になっている. 古いファイルディスクリプタが不要であれば close しなければ,古いファイルディスクリプタは有効な状態になっている. 古いファイルディスクリプタを close しても,新しいファイルディスクリプタは有効なままである.
int dup(int oldfd); int dup2(int oldfd, int newfd);
dup はファイルディスクリプタとして使用されていない最小の値を使用し,dup2 は newfd として指定された値を使用するという点だけが異なる.
dup2 を使用したリダイレクションの設定を図示すると,以下のようになる.
以下は,第1引数に指定されたファイルを,wc の標準入力とするプログラムである. 15〜20行目で第1引数に指定されたファイルを open する処理を行っている. 22行目でファイルディスクリプタ 0 をクローズし,再利用可能な状態にしている. 23行目で dup2 を呼び出し,15行目でオープンしたファイルをファイルディスクリプタ 0 からもアクセスできるようにしている. 28行目で15行目のオープンで取得したファイルディスクリプタの方はクローズしている. これによりオープンしたファイルは,ファイルディスクリプタ 0 からのみアクセスできる状態になる. 30行目で execlp を呼び,wc を起動している. ファイルディスクリプタ 0 は15行目でオープンしたファイルとつながっているため,wc の標準入力はそのファイルから読み込まれることになる.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4 #include <fcntl.h>
5
6 main(int argc, char *argv[])
7 {
8 int file_fd;
9
10 if (argc != 2) {
11 printf("Usage: %s file_name\n", argv[0]);
12 exit(1);
13 }
14
15 file_fd = open(argv[1], O_RDONLY);
16 if (file_fd < 0) {
17 perror("open");
18 close(file_fd);
19 exit(1);
20 }
21
22 close(0);
23 if (dup2(file_fd, 0) < 0) {
24 perror("dup2");
25 close(file_fd);
26 exit(1);
27 }
28 close(file_fd);
29
30 execlp("wc", "wc", NULL);
31 }
以下は,上記プログラムの実行結果である.
% ./a.out a.txt
シェルでコマンドを実行する場合,パイプ機能を用いることで,あるコマンドの出力を別のコマンドの入力とすることができる. 例えば以下のように ls の結果を wc の入力にすることによって,現在のディレクトリにあるファイルやディレクトリの数を数えることができる. 以下の例では .c で終わるCプログラムファイルの数を数えている.
% ls *.c | wc
パイプをもう少し詳しく見てみると,下図のようになる. パイプには入口と出口があり,入口から書いたデータを出口から読み出すことができる. データの流れの方向は,入口から出口の単方向であり,入口から書いた順番で出口からは読み出される.
このパイプを実現しているのが,その名の通り pipe システムコールである.
int pipe(int filedes[2]);
pipe システムコールを呼ぶと,入力と出力それぞれの口(ファイルディスクリプタ)を持つパイプが1本作られる. ファイルディスクリプタは,上記の例だと filedes 配列に格納され,filedes[0] がパイプの出口,filedes[1] がパイプの入口のファイルディスクリプタになる. この関係は,ファイルディスクリプタ 0 が標準入力,ファイルディスクリプタ 1 が標準出力であることと対比させるとわかりやすい. 即ち,filedes[0] から読み,filedes[1] に書く.
プロセス間のパイプの作成を図示すると以下のようになる.
以下のプログラムは,パイプを作成した後 fork をし,子プロセスから親プロセスへ文字列を送るプログラムである.
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 int pipe_fd[2];
5
6 void
7 do_child()
8 {
9 char *p = "Hello, dad!!\n";
10
11 printf("this is child.\n");
12
13 close(pipe_fd[0]);
14
15 while (*p) {
16 if (write(pipe_fd[1], p, 1) < 0) {
17 perror("write");
18 exit(1);
19 }
20 p++;
21 }
22 }
23
24 void
25 do_parent()
26 {
27 char c;
28 int count, status;
29
30 printf("this is parent.\n");
31
32 close(pipe_fd[1]);
33
34 while ((count = read(pipe_fd[0], &c, 1)) > 0) {
35 putchar(c);
36 }
37
38 if (count < 0) {
39 perror("read");
40 exit(1);
41 }
42
43 if (wait(&status) < 0) {
44 perror("wait");
45 exit(1);
46 }
47 }
48
49 main()
50 {
51 int child;
52
53 if (pipe(pipe_fd) < 0) {
54 perror("pipe");
55 exit(1);
56 }
57
58 if ((child = fork()) < 0) {
59 perror("fork");
60 exit(1);
61 }
62
63 if (child)
64 do_parent();
65 else
66 do_child();
67 }
% ./a.out
上記のプログラムを dup2 を使用し,標準入出力をパイプで接続すると以下のようになる. パイプの不要な出入口のクローズ(13, 34行目)と,dup2 によるリダイレクションのためのクローズ(15, 20, 36, 41行目)と,たくさんクローズを呼ぶ必要がある.
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 int pipe_fd[2];
5
6 void
7 do_child()
8 {
9 char *p = "Hello, dad!!\n";
10
11 printf("this is child\n");
12
13 close(pipe_fd[0]);
14
15 close(1);
16 if (dup2(pipe_fd[1], 1) < 0) {
17 perror("dup2 (child)");
18 exit(1);
19 }
20 close(pipe_fd[1]);
21
22 while (*p)
23 putchar(*p++);
24 }
25
26 void
27 do_parent()
28 {
29 char c;
30 int count, status;
31
32 printf("this is parent\n");
33
34 close(pipe_fd[1]);
35
36 close(0);
37 if (dup2(pipe_fd[0], 0) < 0) {
38 perror("dup2 (parent)");
39 exit(1);
40 }
41 close(pipe_fd[0]);
42
43 while ((c = getchar()) != EOF)
44 putchar(c);
45
46 if (wait(&status) < 0) {
47 perror("wait");
48 exit(1);
49 }
50 }
51
52 main()
53 {
54 int child;
55
56 if (pipe(pipe_fd) < 0) {
57 perror("pipe");
58 exit(1);
59 }
60
61 if ((child = fork()) < 0) {
62 perror("fork");
63 exit(1);
64 }
65
66 if (child)
67 do_parent();
68 else
69 do_child();
70 }
プロセスの作成と実行を1度に行うシステムコールがあったとして,同じこと(別に全く同じである必要はないがプロセス間の通信)を実現しようとしたらどうなるであろうか? そのシステムコールにいろいろなオプションや引数を渡せるようにして実現するのであろうか. それとも,より汎用のプロセス間通信機能を使うのであろうか(現在のUNIXにはそのような機能が備わっているが). 少なくとも,forkとexecveが分かれていることにより,リダイレクションやパイプが簡単に実現できることがわかって貰えただろうか.
通常プロセスを終了するために使用される kill コマンドは,kill システムコールを呼ぶことで実現される. kill システムコールは,指定されたプロセスにシグナル呼ばれるイベントを送るためのものである. シグナルについては第5回目の講義で詳しく述べる.
int kill(pid_t pid, int sig);
malloc はできるだけ動的に確保され free により開放されたメモリ領域を使いまわすように設計されているが,現在のヒープ領域だけではメモリ領域が足りなくなった時に,以下のヒープ領域を拡大するためのシステムコールが呼び出される. 呼出し後はヒープ領域が拡大され,新たなメモリ領域確保ができるようになる.
int brk(void *end_data_segment); void *sbrk(ptrdiff_t increment);
以下のライブラリ関数は,単純なプロセスの実行や,パイプを使用してのプロセスの実行を簡単に行えるように用意されている.
FILE *popen(const char *command, const char *type); int pclose(FILE *stream); int system (const char * string);
以下は,プロセスの実行優先順位や利用可能資源の制御,デバッグ等を行うためのシステムコールである.
int nice(int inc); int getrlimit(int resource, struct rlimit *rlim); int getrusage(int who, struct rusage *usage); int setrlimit(int resource, const struct rlimit *rlim); int ptrace(int request, int pid, int addr, int data);
プロセスは,オペレーティングシステムがコンピュータ(プロセッサ)を抽象化し,使いやすくしたものである. コンピュータは入出力機器からのイベント通知を割り込みという仕組みで受け取る. プロセスには,割り込みに相当するイベント通知のメカニズム(ソフトウェア割り込み)として,シグナルが提供されている.
割り込みは入出力機器からのイベント通知のために考え出されたものである. 入出力機器はコンピュータにI/Oコントローラを通して接続されている. 以下の図は単純化したコンピュータの構成を示している.
コンピュータは,に加え,キーボード,マウス,グラフィックスディスプレイ,HDD,ネットワークインタフェースなどの入出力機器(I/Oデバイス)からなる. 入出力機器はI/Oコントローラを通して制御される. プロセッサ,メインメモリ,I/Oコントローラはシステムバスに接続されており,システムバスを通してお互いにデータをやり取りしている.
I/Oコントローラは,システムバスと入出力機器の間でデータの橋渡しをする. 入出力機器は様々な種類のコンピュータに対応するため,標準的なインタフェースを提供している. PCのキーボードやマウスにはPS/2というインタフェースがよく使われていたが,最近のPCやMacintoshではUSBが使われている. HDDはATA,SATAやSCSIというインタフェースがよく使われている. 一方,システムバスはプロセッサ固有のものである. 例えば Macintosh に使われてきた PowerPC というプロセッサのシステムバスと,Intel Pentium 4 のシステムバスは全く異なるものである. PowerPC や Intel Pentium 4 と称されていても,実際はいくつかの異なるシステムバスが使用されている. 入出力機器の標準的なインタフェースに対応するように,I/Oコントローラはプロセッサとのセットで使われるように開発される.
システムバスは以下のバスから構成される.
プロセッサはI/Oコントローラに入出力要求を出し,I/Oコントローラはその要求を解釈し,I/Oデバイスに伝える. I/Oデバイスは入出力要求を処理し,結果をI/Oコントローラに転送し,プロセッサはI/Oコントローラからその結果を受け取る. 下図は,この処理の流れを図示したものである.
プロセッサはI/Oコントローラの状態をチェックし続けることで,処理が終了したかどうかを知る. 従って,プロセッサは,I/Oコントローラ,I/Oデバイスがプロセッサからの入出力要求を処理している間は,プロセッサでの処理を続けられないため待ち時間ができてしまう. このようなI/Oデバイスへの入出力要求の処理方法をポーリング (Polling) と呼ぶ.
通常,I/Oデバイスはプロセッサの処理速度と比較すると非常に遅いため,ポーリングでI/O処理の終了を待っているとプロセッサの使用率を著しく下げてしまう. また,端末からの入力待ちのような場合,プロセッサがユーザからの入力を待つような処理形態では,複数の端末からの入力に対する応答性を良くすることは非常に難しい.
割り込み (interrupt) は,ポーリングの持つ非効率性を解決するため,入出力処理が終了したことをプロセッサに対し通知するために考え出された方法である. I/Oコントローラは,I/Oデバイスとの入出力処理が終了したら,プロセッサに対し割り込み要求を出す. プロセッサは割り込み要求を受け付けると,現在実行中の処理を中断し,割り込みを処理するために予め設定されたプログラムを呼び出し,実行する. この割り込み処理のためのプログラムを,割り込みハンドラとか割り込みサービスルーチン (ISR: Interrupt Service Routine) などと呼ぶ.
■ 割り込みは時間依存の処理を可能にする
割り込みが考え出されてから,時間に依存した処理もできるようになった. 時間を刻むタイマデバイスから一定周期で(例えば1秒ごとに)割り込みがかかるようにすれば,そのタイミングでプロセスの切替をしたり,ポーリングを行ったりすることができるようになる. 割り込みにより,特定のプロセスや特定のデバイスにかかりきりになることなく,公平に有効にプロセッサを分配活用できるようになった.
■ 関数呼び出しは同期処理,割り込みは非同期処理
割り込み処理は本来のプログラムの処理の流れとは無関係に,非同期的 (asynchronous) に発生する. 一方,関数呼び出しは同期的 (synchronous) であり,明示的に関数を呼び出し,呼び出された関数で処理が行われ,関数呼び出しから戻ってくる. 下図は,関数呼び出しと割り込み処理の違いを図示したものである.
ある関数における処理から別の関数(割り込み処理ハンドラもプログラムの中では関数として定義される)が呼び出されるという処理の流れだけを見ると,関数呼び出しも割り込み処理も違いはない. しかしながら,関数呼び出しの場合には関数を呼び出すという命令が入っているのに対し,割り込み処理の場合は割り込まれたプログラムには割り込み処理ハンドラを呼び出すような命令は一切ない. いつどこで割り込まれるかわからないのが,割り込みの特徴である.
OSカーネルで処理を行ううえで,いつでも割り込まれてしまうのでは,データの一貫性を保つことができないので,プロセッサには割り込みを禁止する命令が用意されている.
割り込みとは別に,アクセスが許可されていない番地にアクセスしようとしたとか,0による除算をしようとしたとか,不正な命令(例えば特権が必要な命令)を実行しようとしたとかの理由で,プログラムの実行中にそのプログラムに原因が起因するエラーが起こることがある. このようなエラーのことを例外 (exception) と呼ぶ. 例外が発生した場合,OSカーネルの例外ハンドラが起動され対処する.
割り込みと例外が良く似ている点は,OSカーネルの割り込み又は例外ハンドラが起動されるという点,そしてこれらのハンドラを呼び出す命令がプログラム中には含まれていないという点である. 異なっているのは,割り込みの場合は割り込みハンドラが起動されるのは,デバイスなどプログラム外部の要因であるのに対し,例外の場合はプログラムの実行にその要因があるという点である.
ハードウェアからの割り込みはや例外はOSカーネルにより処理される. ハードウェアを直接操作できるのはOSカーネルだけであるので,通常のユーザプロセスがハードウェアからの割り込みを直接受けることはない. 例外は,その要因となったプログラムが処理することが可能な場合もあるが,プログラムに共通する処理も多いため,通常OSカーネルにより処理される.
しかしながら,割り込みや例外の概念はユーザプロセスとして動作するプログラムにも便利である. ある一定時間ごとに割り込みを発生させることができれば,現在の処理を継続しながら別の処理,例えばプロンプトを点滅させたり,アニメーションを実行したり,又は割り込みをサポートしていないデバイスに対しポーリングを行ったりというようなこと,ができる. また,非同期的に命令を送りそれに応じた処理を行わせるためにも,割り込みの概念は使用できる. 例外が起こった場合に,そのイベントに対するプログラム独自の対処をしたい場合もある.
■ 割り込みを抽象化したのがシグナル
UNIXではプロセッサとメモリという基本的なコンピュータはプロセスとして抽象化されているが,同じように割り込み及び例外を抽象化したのがシグナル (signal) である. 割り込みハンドラに相当するのがシグナルハンドラである. 一般的に使用される割り込みや例外の種類に応じたシグナルがOSカーネルにより定義されている. プロセスはそれぞれのシグナルの種類に対しシグナルハンドラをOSカーネルに登録することができる. プロセスは,実行中のプログラムに起因する例外や,プロセス外部からのイベントをシグナルとして受け取り,OSカーネルに登録したシグナルハンドラが起動される.
プロセス外部からのイベントとして良く使用されているのが,キーボードから Ctrl-C や Ctrl-Z によるプロセス実行の中止又は中断である. これらのキーボードからの入力は,OSカーネルに含まれるデバイスを制御するデバイスドライバにより処理され,プロセスにはシグナルとして通知される.
SIGNAL(3) BSD Library Functions Manual SIGNAL(3)
NAME
signal -- simplified software signal facilities
LIBRARY
Standard C Library (libc, -lc)
SYNOPSIS
#include <signal.h>
void (*
signal(int sig, void (*func)(int)))(int);
or in the equivalent but easier to read typedef'd version:
typedef void (*sig_t) (int);
sig_t
signal(int sig, sig_t func);
DESCRIPTION
This signal() facility is a simplified interface to the more general
sigaction(2) facility.
.... 一部省略 ....
No Name Default Action Description
1 SIGHUP terminate process terminal line hangup
2 SIGINT terminate process interrupt program
3 SIGQUIT create core image quit program
4 SIGILL create core image illegal instruction
5 SIGTRAP create core image trace trap
6 SIGABRT create core image abort program (formerly SIGIOT)
7 SIGEMT create core image emulate instruction executed
8 SIGFPE create core image floating-point exception
9 SIGKILL terminate process kill program
10 SIGBUS create core image bus error
11 SIGSEGV create core image segmentation violation
12 SIGSYS create core image non-existent system call invoked
13 SIGPIPE terminate process write on a pipe with no reader
14 SIGALRM terminate process real-time timer expired
15 SIGTERM terminate process software termination signal
16 SIGURG discard signal urgent condition present on socket
17 SIGSTOP stop process stop (cannot be caught or ignored)
18 SIGTSTP stop process stop signal generated from keyboard
19 SIGCONT discard signal continue after stop
20 SIGCHLD discard signal child status has changed
21 SIGTTIN stop process background read attempted from control terminal
22 SIGTTOU stop process background write attempted to control terminal
23 SIGIO discard signal I/O is possible on a descriptor (see fcntl(2))
24 SIGXCPU terminate process cpu time limit exceeded (see setrlimit(2))
25 SIGXFSZ terminate process file size limit exceeded (see setrlimit(2))
26 SIGVTALRM terminate process virtual time alarm (see setitimer(2))
27 SIGPROF terminate process profiling timer alarm (see setitimer(2))
28 SIGWINCH discard signal Window size change
29 SIGINFO discard signal status request from keyboard
30 SIGUSR1 terminate process User defined signal 1
31 SIGUSR2 terminate process User defined signal 2
32 SIGTHR terminate process thread interrupt
.... 以下省略 ....
signal システムコールは,シグナルをサポートするために最初に作られたシステムコールである.
typedef void (*sig_t)(int); sig_t signal(int sig, sig_t func);
シグナルハンドラを変更するシグナルと新しいシグナルハンドラを引数に指定して呼び出すと,古いシグナルハンドラが返される. signal システムコールの引数と戻り値の型は sig_t であり,これは int 型を引数に取り値を返さない(つまり void型の)関数へのポインタ(アドレス)という意味である. 即ち,シグナルハンドラは以下のようにプロトタイプ宣言されるような関数ということになり,このような関数へのポインタが,signal システムコールの引数や戻り値になる. シグナルハンドラの引数は,送られてきたシグナルの番号である.
void signal_handler(int);
古いシグナルハンドラの値としては次が返されることもある:
シグナルと共に使われるシステムコールに pause がある. pause を呼び出すとシグナルを受け取るまでプロセスの実行をブロックする. シグナルを受け取ると,シグナルハンドラの実行後に,pauseから戻る.
int pause(void);
以下は signal と pause を使ったプログラム例である.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <signal.h>
4
5 volatile sig_atomic_t sigint_count = 3;
6
7 void
8 sigint_handler(int signum)
9 {
10 printf("sigint_handler(%d): sigint_count(%d)\n",
11 signum, sigint_count);
12
13 if (--sigint_count <= 0) {
14 printf("sigint_handler: exiting ... \n");
15 exit(1);
16 }
17
18 #if 0 /* For the original System V signal */
19 signal(SIGINT, &sigint_handler);
20 #endif
21 }
22
23 main()
24 {
25 signal(SIGINT, &sigint_handler);
26
27 for (;;) {
28 printf("main: sigint_count(%d), calling pause ....\n",
29 sigint_count);
30
31 pause();
32
33 printf("main: return from pause. sigint_count(%d)\n",
34 sigint_count);
35 }
36 }
5行目の volatile sig_atomic_t は見慣れないかもしれないが,その説明は後述する.
コンパイル,実行すると以下のようになる. Ctrl-C は ^C として表示される. 送られてきたシグナルの番号がシグナルハンドラ sigint_handler の引数になるため,SIGINT の番号である 2 が sigint_handler の引数として渡されているのがわかる.
% ./a.out^Csigint_handler(2): sigint_count(3) main: return from pause. sigint_count(2) main: sigint_count(2), calling pause ....
signal システムコールの最初の(しかしながら System V 系の UNIX まで継承された)仕様は,多くの問題を持っていた.
例えば read システムコールを呼び出し,入力待ちの状態でブロックしている時に,シグナルが通知された場合,シグナルは処理され,そのシグナルに対応するシグナルハンドラが起動される. この場合,ブロック状態になっていたシステムコールはキャンセルされ EINTR というエラーが返されるようになっていた.
あるシグナルに対応したシグナルハンドラを実行中に,また同じシグナルが通知された場合,同じシグナルハンドラを起動してしまうと,データの一貫性などに問題が生じてしまう. そのため,シグナルハンドラは一度呼び出されるとデフォルトの動作にリセットされるようになっていた. そのため,シグナルハンドラが起動される度に signal システムコールでシグナルハンドラを設定し直す必要があった(上記プログラムの18〜20行目).
しかしながら,この方法ではデフォルトの動作がプロセスの終了であった場合,シグナルハンドラを実行中に同じシグナルを受けたらプロセスが終了してしまうことになる.
そこでシグナルを無視するようにシグナルハンドラの先頭で SIG_IGN を設定すれば良いように思われるがが,この場合は
System V とは別の系列のUNIXにBSD (Berkeley Software Distribution) というものがあった. BSD UNIXでは上記のような問題に対し signal の動作を変えることで対応しようとした.
システムコールはキャンセルされない. シグナルハンドラ実行後に,システムコールの実行は継続される(ブロック状態に戻る).
シグナルハンドラの実行中に同じシグナルが通知されたら,そのシグナルは保留される. 現在実行中のシグナルハンドラ処理の終了を待ち,もう一度シグナルハンドラを起動する. シグナルハンドラはリセットされない.
signal システムコールの混乱状態を解決するために,POSIX では sigaction という新しいシステムコールを導入した. sigaction で導入されたシグナルのことを,旧来のシグナルメカニズムと区別するためにPOSIXシグナルと呼ばれることがある. POSIX準拠のシステムであれば sigaction を使用すべきであり,signal はもはや使用すべきではない.
int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact);
sigaction システムコールは,第1引数にシグナル番号,第2引数に設定するシグナルの動作を指定して呼び出すと,第3引数に古い設定が返される.
上記の問題点におけるPOSIXシグナルのデフォルトの動作は次のようになっている.
古い signal と同じく,システムコールはキャンセルされ EINTR というエラーが返される.
この点ついてはBSD UNIXと同じでる. シグナルハンドラの実行中に同じシグナルが通知されたら,そのシグナルは保留され,現在実行中のシグナルハンドラ処理の終了を待ち,もう一度シグナルハンドラを起動する. また,シグナルハンドラはリセットされない.
シグナルの動作は以下の struct sigaction を用いて設定する.
struct sigaction {
union {
void (*__sa_handler)(int);
void (*__sa_sigaction)(int, struct __siginfo *, void *);
} __sigaction_u; /* signal handler */
int sa_flags; /* see signal options below */
sigset_t sa_mask; /* signal mask to apply */
};
#define sa_handler __sigaction_u.__sa_handler
#define sa_sigaction __sigaction_u.__sa_sigaction
古い signal のプログラムを,sigaction で sa_handler を使うように変更すると以下のようになる. 基本的には全く同じであるが,若干異なっている.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <signal.h>
4 #include <string.h>
5
6 volatile sig_atomic_t sigint_count = 3;
7
8 void
9 sigint_handler(int signum)
10 {
11 printf("sigint_handler(%d): sigint_count(%d)\n",
12 signum, sigint_count);
13
14 if (--sigint_count <= 0) {
15 printf("sigint_handler: exiting ... \n");
16 exit(1);
17 }
18 }
19
20 main()
21 {
22 struct sigaction sa_sigint;
23
24 memset(&sa_sigint, 0, sizeof(sa_sigint));
25 sa_sigint.sa_handler = sigint_handler;
26 sa_sigint.sa_flags = SA_RESTART;
27
28 if (sigaction(SIGINT, &sa_sigint, NULL) < 0) {
29 perror("sigaction");
30 exit(1);
31 }
32
33 for (;;) {
34 printf("main: sigint_count(%d), calling pause ....\n",
35 sigint_count);
36
37 pause();
38
39 printf("main: return from pause. sigint_count(%d)\n",
40 sigint_count);
41 }
42 }
上記プログラムの実行結果は,古い signal を用いた場合と同一であるので,省略.
同じプログラムを,sigaction で sa_sigaction を使うように変更したプログラムは以下のようになる.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <signal.h>
4 #include <string.h>
5
6 volatile sig_atomic_t sigint_count = 3;
7
8 void
9 sigint_action(int signum, siginfo_t *info, void *ctx)
10 {
11 printf("sigint_handler(%d): sigint_count(%d) signo(%d) code(0x%x)\n",
12 signum, sigint_count, info->si_signo, info->si_code);
13
14 if (--sigint_count <= 0) {
15 printf("sigint_handler: exiting ... \n");
16 exit(1);
17 }
18 }
19
20 main()
21 {
22 struct sigaction sa_sigint;
23
24 memset(&sa_sigint, 0, sizeof(sa_sigint));
25 sa_sigint.sa_sigaction = sigint_action;
26 sa_sigint.sa_flags = SA_RESTART | SA_SIGINFO;
27
28 if (sigaction(SIGINT, &sa_sigint, NULL) < 0) {
29 perror("sigaction");
30 exit(1);
31 }
32
33 while (1) {
34 printf("main: sigint_count(%d), calling pause ....\n",
35 sigint_count );
36
37 pause();
38
39 printf("main: return from pause. sigint_count(%d)\n",
40 sigint_count );
41 }
42 }
コンパイル,実行すると以下のようになる. Ctrl-C は ^C として表示される. 通知されたシグナルについてより多くの情報を引数として受け取れるが,その詳細については SIGACTION(2) を参照.
% ./a.out
受け取りたくないシグナルは無視することができる. その場合シグナルハンドラに SIG_IGN を設定する.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <signal.h>
4 #include <string.h>
5
6 volatile sig_atomic_t sigint_count = 3;
7
8 main()
9 {
10 struct sigaction sa_ignore;
11
12 memset(&sa_ignore, 0, sizeof(sa_ignore));
13 sa_ignore.sa_handler = SIG_IGN;
14
15 if (sigaction(SIGINT, &sa_ignore, NULL) < 0) {
16 perror("sigaction");
17 exit(1);
18 }
19
20 while (1) {
21 printf("main: sigint_count(%d), calling pause() ....\n",
22 sigint_count );
23
24 pause();
25
26 printf("main: return from pause(). sigint_count(%d)\n",
27 sigint_count );
28 }
29 }
コンパイル,実行すると以下のようになる. Ctrl-C は ^C,Ctrl-Z は ^Z として表示される.
% ./a.out^Z Suspended % jobs
以下のように,SIG_IGN の値は 1 であり,またデフォルトの動作を表す SIG_DFL の値は 0 である. sigaction は古い設定を返すが,シグナルを無視またはデフォルトの設定の場合は,これらの値が sa_handler に入ってくる.
#define SIG_DFL (void (*)(int))0 #define SIG_IGN (void (*)(int))1
プロセスへシグナルを送るためには kill システムコールを使用する. 引数に送り先のプロセスIDと送るシグナルを指定する.
int kill(pid_t pid, int sig);
以下は,引数にプロセスIDを指定し,そのプロセスに対し SIGINT を送るプログラムである.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <signal.h>
4
5 main(int argc, char *argv[])
6 {
7 pid_t pid;
8
9 if (argc != 2) {
10 printf("Usage: %s pid\n", argv[0]);
11 exit(1);
12 }
13
14 pid = atoi(argv[1]);
15
16 if (pid <= 0) {
17 printf("Invalid pid: %d\n", pid);
18 exit(1);
19 }
20
21 if (kill(pid, SIGINT) < 0) {
22 perror("kill");
23 exit(1);
24 }
25 }
上記のプログラムで,シグナルハンドラ内で値が変更される変数は,以下のように宣言している.
volatile sig_atomic_t sigint_count = 3;
sig_atomic_t は,割り込まれずに書き込みが可能な変数の型である. volatile は型修飾子と呼ばれるもので,型の前に付けて使用する. volatile を付けることで,コンパイラによる最適化が抑止され,この場合 sigint_count に対する読み書きは,必ずメモリに対して行なわれるようになる.
このような宣言が必要な理由は,シグナルハンドラの呼び出しが,関数呼び出しのようにプログラムの制御の流れに沿ったものではなく,プログラム外部のイベントに起因し非同期的に起こるものだからである. プログラムの制御の流れに沿っている場合,変数への読み書きはコンパイラの制御下にあるため,最適化により一時的にレジスタに置かれている変数の値が正しく参照される. しかし,シグナルハンドラは,本来のプログラムの制御の流れとは無関係に,プログラムの実行に割り込んで呼び出される. 最適化により変数の値が一時的にレジスタに置かれているところにシグナルハンドラの呼び出しが起こった場合,シグナルハンドラはその最新の値にアクセスすることはできない. また,シグナルハンドラが変数の値を書き換えたとしても,割り込まれたプログラムはその変更に気がつかないこともあり得る.
volatile 宣言された変数に対する読み書きは,必ずメモリに対して行なわれるため,シグナルハンドラによる割り込みが起こっても,最新の値を参照することができる. また,sig_atomic_t は割り込まれずに書き込みが可能な変数の型を提供するため,変数の読み書きの途中で割り込まれることがない. そのため,一貫性のある値を読み書きすることができる.
シグナルハンドラは,本来のプログラムの制御の流に割り込んで呼び出されるため,プログラムの制御自体に矛盾を引き起こす場合もある. そのような矛盾を引き起こしてしまうライブラリ関数,システムコールは数多くあるため,シグナルハンドラ内で使用可能なライブラリ関数,システムコールは制限されている.
シグナルハンドラ内で使用可能な関数のリストについては sigaction(2) を参照のこと.
例えば,printf はシグナルハンドラ内で使用可能な関数のリストには含まれておらず,シグナルハンドラ内で使用するべきではない. write は使用可能なので,メッセージを出力する必要がある場合は,write を用いる.
ある一定時間ごとに割り込みを発生させ,現在の処理を継続しながら別の処理,例えばプロンプトを点滅させたり,アニメーションを実行したり,又は割り込みをサポートしていないデバイスに対しポーリングを行ったりというようなこと,がしたい場合にはインターバルタイマという機能を使用する. インターバルタイマは setitimer システムコールを用いて設定できる.
int setitimer(int which, const struct itimerval *value, struct itimerval *ovalue);
インターバルタイマは第2引数で指定した時間が経つ(残り時間が 0 になる)とシグナルで通知するが,どのような時間なのかを,第1引数の which で以下のタイマーから1つを設定する.
第2引数で時間を指定するために使用する struct itimerval とその中で使われている struct timeval の定義は以下のようになっている.
struct itimerval {
struct timeval it_interval; /* next value */
struct timeval it_value; /* current value */
};
struct timeval {
long tv_sec; /* seconds */
long tv_usec; /* microseconds */
};
it_value が 0 になると,which で指定されるタイマに対応するシグナルが通知される. そして,it_interval の値が次の時間として設定される. it_value, it_interval どちらの値も 0 になったタイマは停止する.
タイマをキャンセルするためには it_value に 0 を指定して,setitimer を呼び出せば良い.
以下は,ITIMER_REAL で実際の時間で 1 秒ごとにシグナルを受け,10回シグナルを受け取ると終了するプログラムである. 終了する前にタイマをキャンセルしている.
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <signal.h>
4 #include <string.h>
5 #include <sys/time.h>
6
7 volatile sig_atomic_t alrm_count = 10;
8
9 void alrm()
10 {
11 alrm_count--;
12 }
13
14 main()
15 {
16 struct sigaction sa_alarm;
17 struct itimerval itimer;
18
19 memset(&sa_alarm, 0, sizeof(sa_alarm));
20 sa_alarm.sa_handler = alrm;
21 sa_alarm.sa_flags = SA_RESTART;
22
23 if (sigaction(SIGALRM, &sa_alarm, NULL) < 0) {
24 perror("sigaction");
25 exit(1);
26 }
27
28 itimer.it_value.tv_sec = itimer.it_interval.tv_sec = 1;
29 itimer.it_value.tv_usec = itimer.it_interval.tv_usec = 0;
30
31 if (setitimer(ITIMER_REAL, &itimer, NULL) < 0) {
32 perror("setitimer");
33 exit(1);
34 }
35
36 while (alrm_count) {
37 pause();
38 printf("%d: %d\n", alrm_count, time(NULL));
39 }
40
41 itimer.it_value.tv_sec = itimer.it_interval.tv_sec = 0;
42 itimer.it_value.tv_usec = itimer.it_interval.tv_usec = 0;
43
44 if (setitimer(ITIMER_REAL, &itimer, NULL) < 0) {
45 perror("setitimer");
46 exit(1);
47 }
48 }
コンパイル,実行するといかのようになる.
% ./a.out